
一 前言
前段时间,妈妈的手机不慎摔坏,需要更换一部新手机。为此,姐姐决定为妈妈挑选一款合适的手机,并征求了我的意见。考虑到妈妈对手机的功能需求相对简单,平时主要使用微信、抖音等几个常见应用,且红米系列手机在中低端市场,特别是在中老年用户群体中口碑较好,便趁着促销活动时,我们选择了红米 Note 13 Pro+。
然而,这次的使用体验却令人失望。妈妈经常遇到屏幕无法滑动的情况,手机信号也很差,整体表现不如之前的手机。这让姐姐有些吃力不讨好,我也开始思考问题出在哪里。为了深入分析红米 Note 13 Pro+ 的评价和使用情况,我决定进行一项相关红米 note13pro+ 视频内容的数据分析项目。
通过综合运用文本挖掘、情感分析和 Tableau 数据可视化等技术,我将构建一个多维度的数据分析框架,确保结果的准确性和全面性。我希望这次分析不仅能揭示红米 Note 13 Pro+ 的真实使用体验与评价,还能为社交媒体进行产品推广提供有价值的参考。
二 数据源 & 数据获取
项目使用的数据来源于小白测评在 B 站发布的视频“「小白」 红米 Note 13 Pro+ 测评:曲屏 IP68+ 天玑 7200 Ultra”的弹幕和评论信息,视频链接为
https://www.bilibili.com/video/BV1Qh4y1A7S8/?spm_id_from=333.337.search-card.all.click&vd_source=d436eb6ac17e9c5e2b3c728ce1be516f。
对于信息获取,可能是 B 站对于爬虫这方面做了限制,加之本身自己刚学爬虫没多久,拖了一个多月也没有解决。最后找了大佬帮忙,才顺利获取 5000 条弹幕内容和 6000 多条评论内容及信息。
三 弹幕信息探索 & 预处理
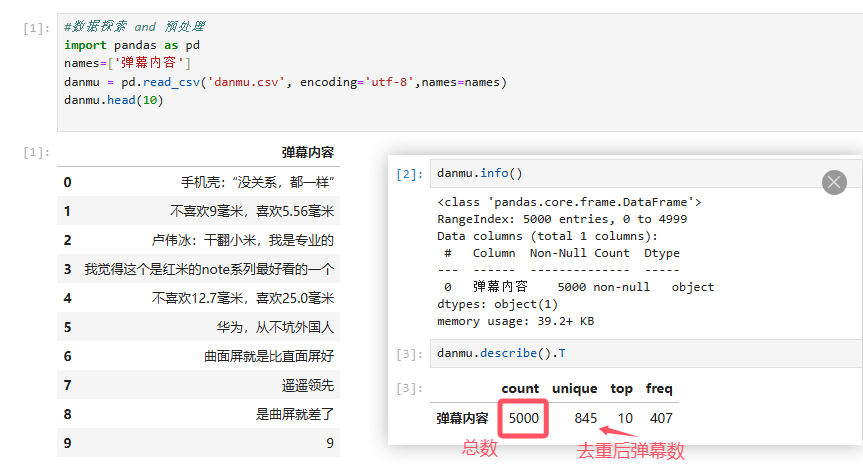
首先将得到的弹幕内容数据导入到 pandas,先观察一下弹幕长什么样。可以看到有涉及到手机厚度,屏幕,颜值方面的评价,很符合电商产品的评价情况。接着使用 info 和 describe 查看数据的整体情况。虽然弹幕信息的数据结构比较简单,但在后面涉及到机器学习深度学习后,面对大量的数据集,info 和 describe 是在探索任何数据集之前必须用到的。通过运行代码可以看到数据不存在缺失值,弹幕总量为 5000 条,去重后仅有 845 条,介于弹幕内容较短,且有跟风趋同的情况,也在情理之中。
四 SnowNLP 情感分析
数据探索完,进入正题。我们先使用 SnowNLP 这个库对这些弹幕做情感分析。简单说就是用模型对每条弹幕进行训练并对这条弹幕所代表的情感打分,分数越高越积极 (正面),分数越低越消极 (负面)。SnowNLP 在新闻评论舆情分析,电商评论等场景用的最多最广。这里我从 GitHub 上找到了用于训练测试的电商评论类数据集,保存为 text.csv 文件,内容包括电商商品评论以及情感值(0 or 1)。通过测试结果来看,SnowNLP 自带的模型恰好可以用于电商商品评论(准确率达 87%)。倘若需要对其他类型文本进行情感分析,则需要自行训练模型并测试。

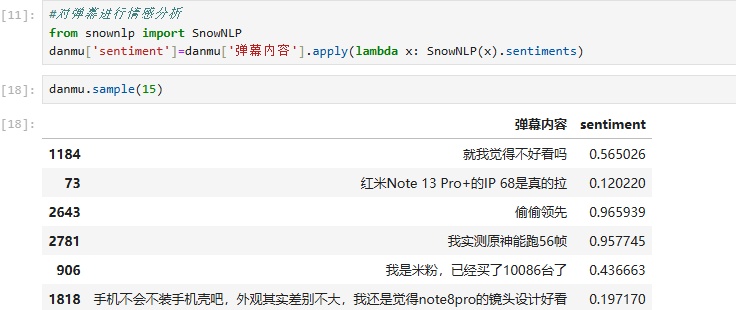
接下来对弹幕进行情感分析,并随机抽取部分样本查看情感值,可以看到评价还是褒贬不一的。并且对于评分还是没有那么精准。毕竟没有花大精力去训练模型,我想后续在机器学习的自然语言处理方面在深入了解,用更大的数据量训练模型,调节好各种参数,对应的评分将更加精准。
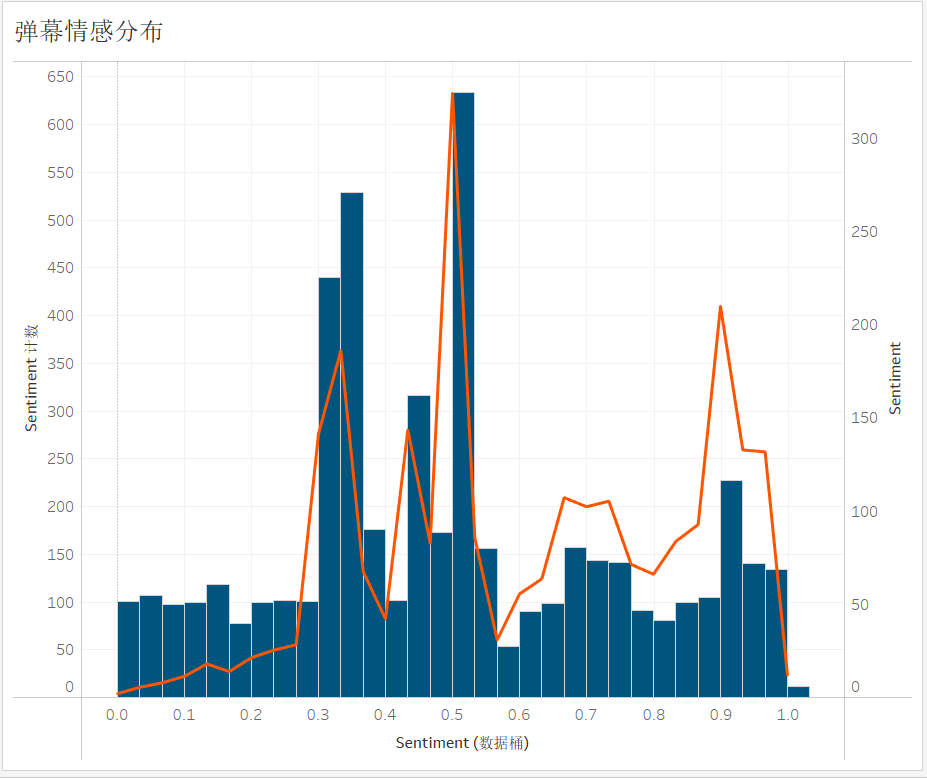
将最终得到的数据保存到 'danmu_data.csv' 文件后,导入 Tableau,通过操作,便得到了整体情感分布情况。这里也可以使用 python 中的 matplotlib 等可视化库实现。根据这张概率密度分布图可以直观的发现,在 0.3-0.5 附近,柱子最高,分布最密,表明弹幕整体情感方向比较集中在中等偏下,弹幕数据的整体情感倾向偏向负面,并非我盲目以为的好评如潮。
五 基于 Gensim 的 LDA 主题模型
分析完弹幕情感倾向,更进一步,使用 Gensim 来对这份弹幕数据做一个主题分析。
基于 Gensim 的 LDA(Latent Dirichlet Allocation)主题模型是一种用于文本数据分析的无监督机器学习方法,旨在发现文档集中隐藏的主题结构。
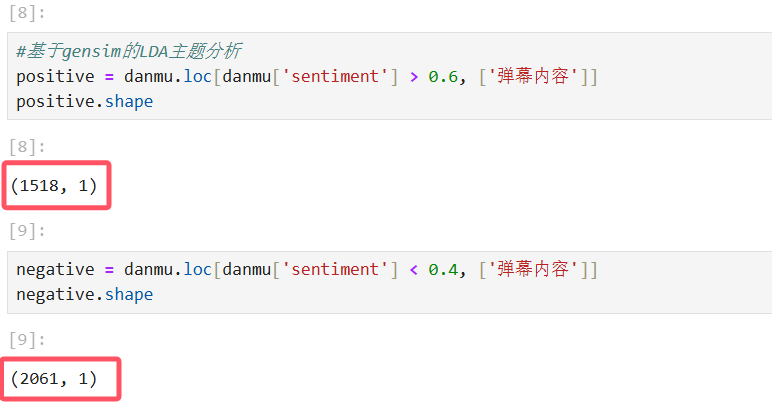
这里我们首先将弹幕情感值大于 0.6 的归为积极类,小于 0.4 的归为消极类。这里可以发现,筛选后的积极弹幕有 1518 条,消极弹幕有 2061 行,要远多于积极弹幕
接下来我们要对弹幕进行分词处理,因为一般来说,对一个新闻或者文章进行主题提炼,想要更直观快速的了解主题内容,关键词是一个很好的选择。我们先用 jieba.lcut() 对弹幕内容进行分词操作,然后转化为 pandas 中的 dataframe 格式,便于后续操作。
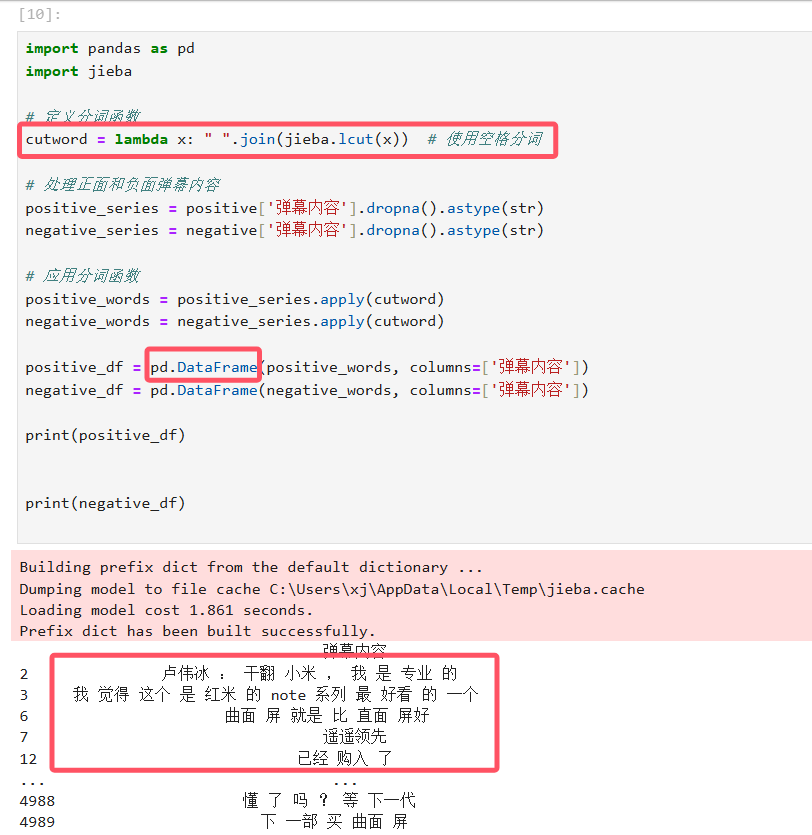
接着我们导入中文停用词并将其转换为一个列表,列表开头添加了两个空格字符,便于后面对空格进行处理,停用词文件可在 GitHub 中找到。
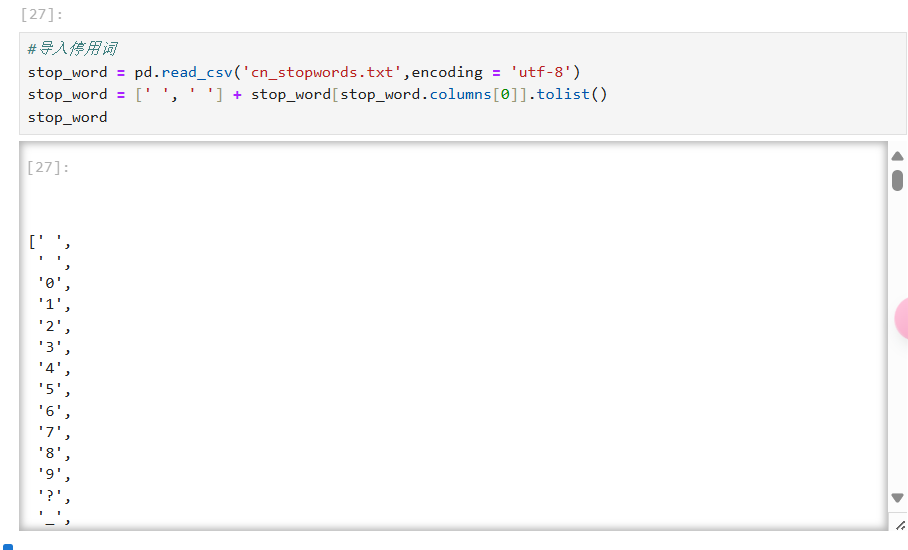
然后利用正则表达式和导入停用词,将积极文本里的那些语气词,介词等等无意义的文字和标点符号删除。消极文本做同样的处理。
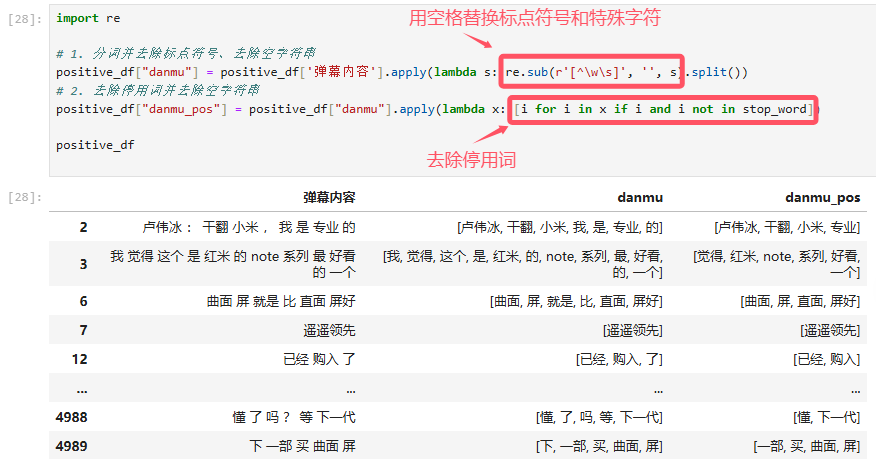
然后,使用 for 循环,分别将分词后的结果放入积极 / 消极词典中

紧接着,我们就可以开始构建情感词典了,这里用到的是 gensim 里面的 corpora.Dictionary,得出来的 pos_dict 结果是一个惰性对象,因此需要 [*pos_dict] 将其展看看到结果。那么什么是惰性对象呢?在 gensim 中,Dictionary 是基于内存高效的设计,它通过惰性加载来存储词汇及其 ID 映射。当你操作 Dictionary 对象时,它不会立即在内存中展现出所有的词汇和频率等信息,而是等到你真正需要查看、操作或转换数据时,才会计算和加载相关的信息。
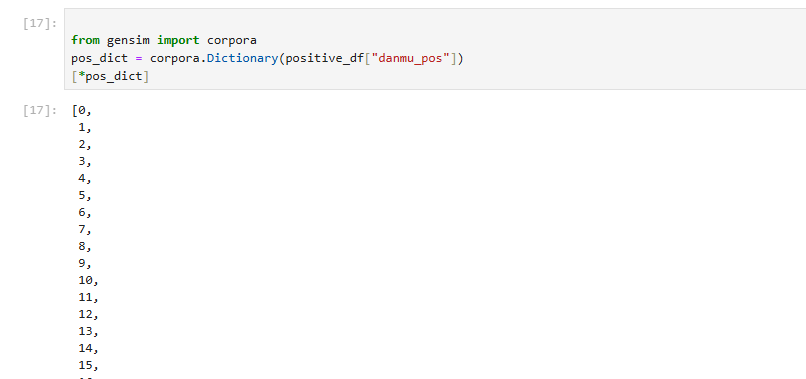
得到情感词典后,构建训练要用的语料库
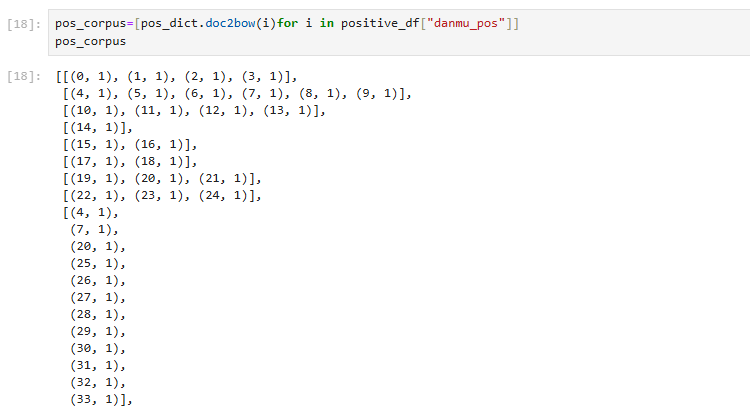
最后,使用 LDA(文本主题)模型进行训练(机器学习),训练对象就是语料库,num_topics 就是想要分成多少个主题,id2word 就是上面构建的情感词典。

最后输出一下每个主题。主题模型分析就 OK 了。


总的来说,LDA 是一种非常强大的主题建模技术,可以从大量文档中自动发现隐藏的主题结构。Gensim 提供了高效的实现,能够快速训练和推理。通过适当的文本预处理和参数调整,LDA 可以在许多实际应用中获得有意义的主题。
弹幕数据分析的最后一步,就是制作词云图了。对于前面处理的数据,用来制作词云图仍有部分问题,做出来的效果不理想,因此这里重新对弹幕数据进行处理。
首先,通过正则表达式去除掉弹幕中的非中文字符,只保留中文部分。然后,使用 jieba 分词库将文本拆分成词语列表。接着,过滤掉一些常见的、对分析没有实际意义的词语(停用词),最后将处理后的结果保存在 cutword 列中,并输出分词后的前几行结果查看。
然后将 cut_word 列表中每个弹幕的分词结果(即每个句子分割成的词)提取出来,并将它们存储到一个新的列表 text_list 中。通过两层循环,代码首先遍历 cut_word 中的每个分词列表,再遍历每个分词列表中的每个词,最终把所有词汇添加到 text_list 中。最后,代码输出 text_list 列表中的前 10 个词语。

过滤停用词并将处理后的数据保存为 '弹幕词云.csv' 文件
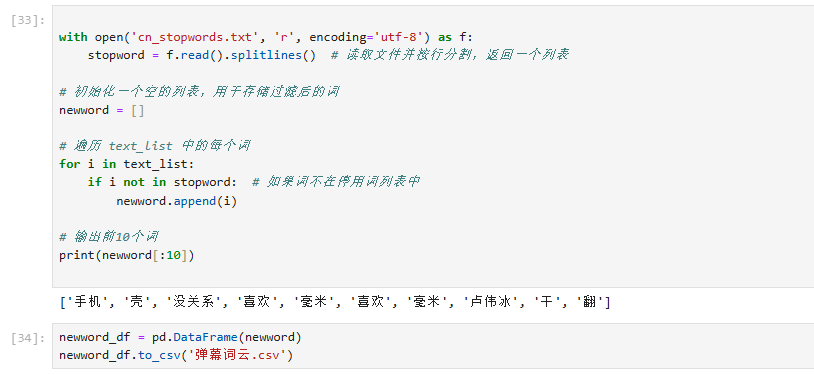
将数据导入到 Tableau 中,制作相关图表。
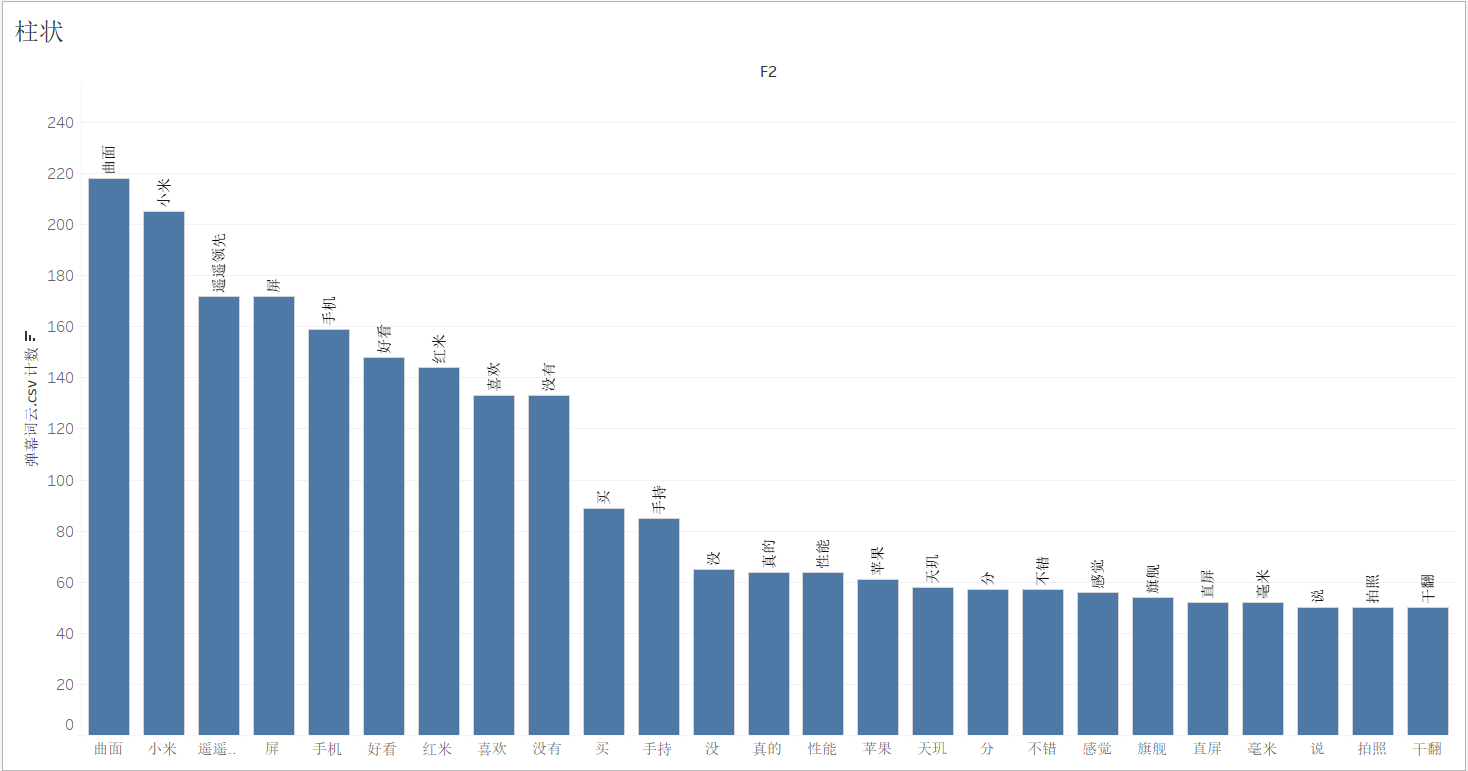
首先是词云图的绘制,这里我们将词语分别拖拽到标记栏的颜色和标签中,颜色是区别开每个词语,标签则是将文字内容显示出来。将 CNT 词云技术拖到大小模块,这样就可以根据词语出现的频率设置词云的大小,词云图制作出来了。有一点需要注意的是,因为词语内容实在太多,因此加入了数量筛选器,只保留出现次数大于 20 的词云。

如果觉得数量上的显示没有太明显,这里顺便制作了一张柱状图。只需将计数拖到行这一栏,词云内容拖到列即可。同样使用筛选器,保留出现次数大于 50 的词语。
六 评论数据可视化(点赞,用户等级,性别,ip 分布)
首先导入评论数据,看看数据长什么样。
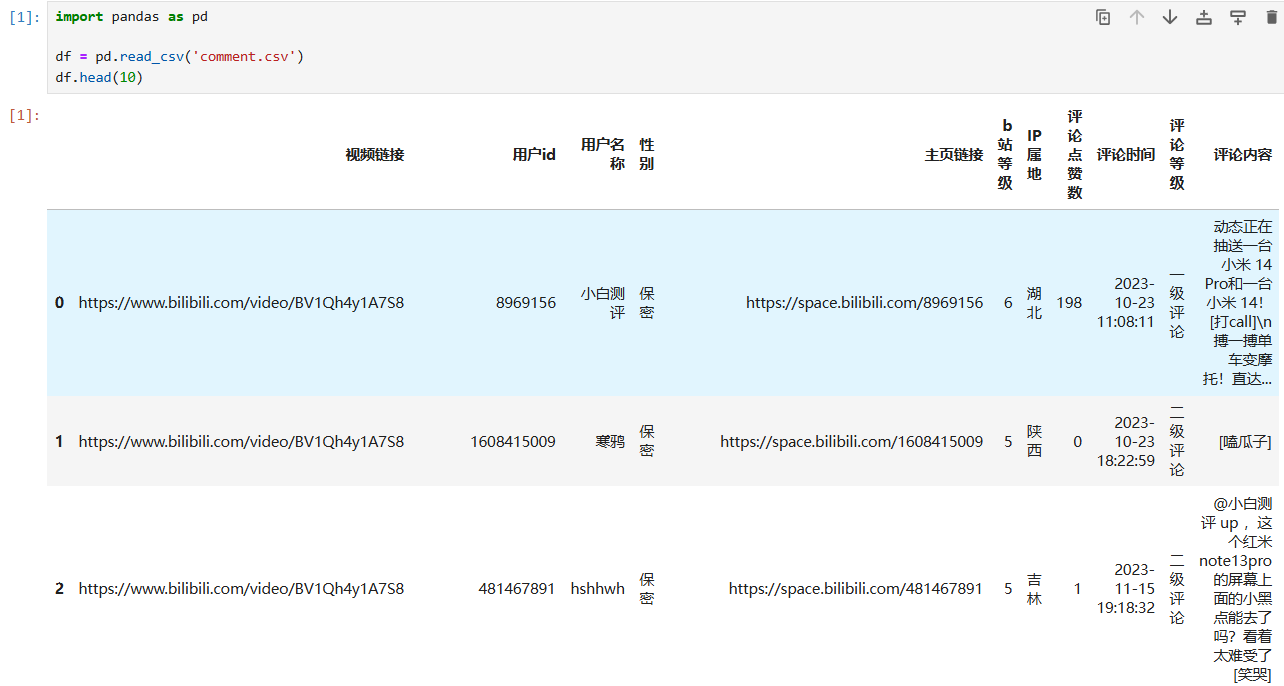
可以看到数据包括视频链接,用户 id,用户名称,性别等,这里删除对我们无用的视频链接, 主页链接,用户 id,评论时间,评论等级。得到的结果如下
简单的查看一下数据统计
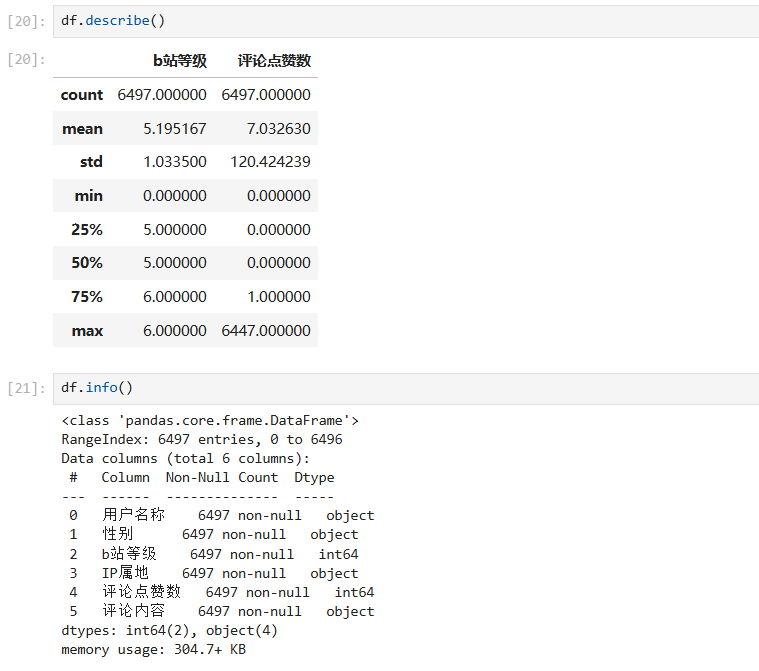
可以看到 6497 条评论里,用户的平均等级达到了恐怖的 5.19,有 75% 用户等级为 5 级 6 级。可见关注数码频道的网友大多还是在网络上比较活跃的,萌新较少,评论也相较而言更加有参考意义。每条评论平均点赞数为 7 个,最高点赞数为 6447。
因为使用 Tableau 可以实现大部分需求,更直观的展示,就不在对数据进行处理,直接将结果保存到 csv 文件并导入 Tableau。
评论热度 top
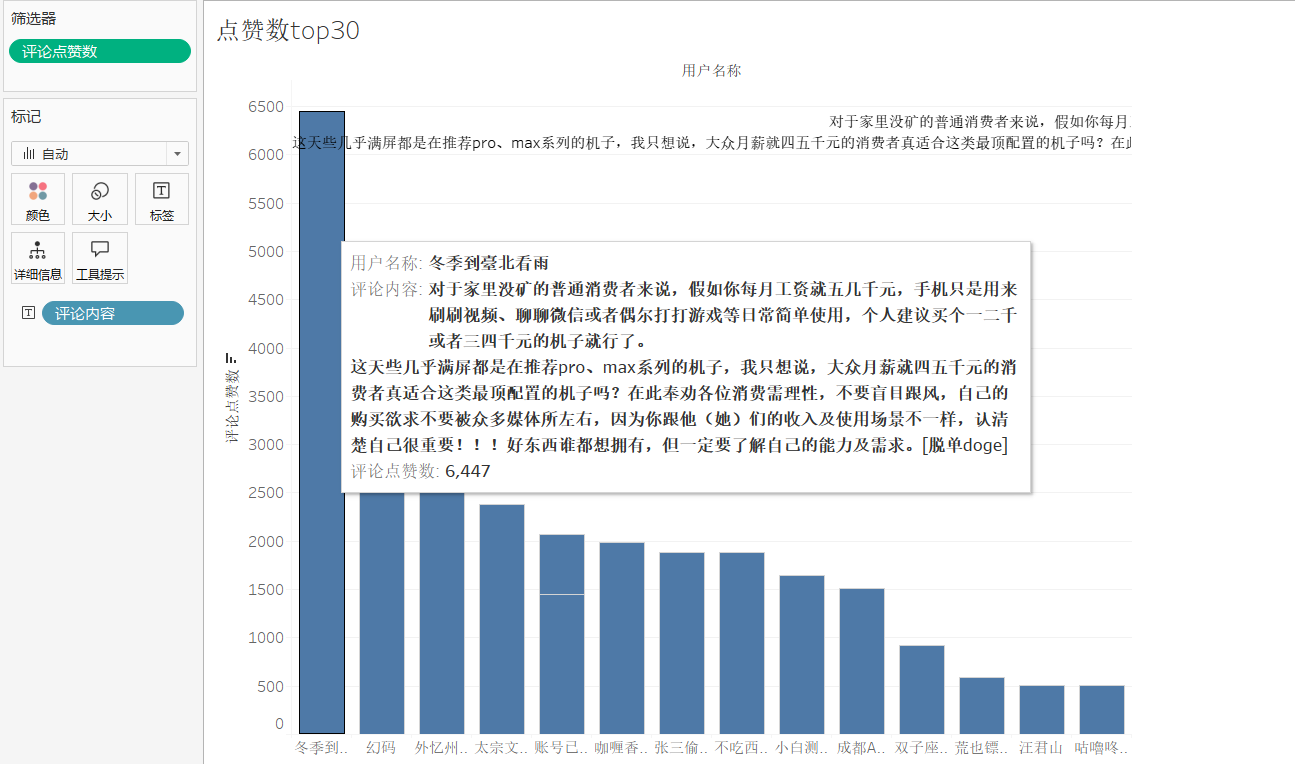
可以看到点赞 top1 的评论内容,非常的客观,冷静。根据前面的分析,也不难看出,有很多人对这台手机的期望值太高了,脱离了这台手机的设计初心。个人看来 1000 多的手机,消费对象本就是那些对手机功能要求不高的中老年人以及预算没有那么多的年轻人。很多人却拿 2000 多,3000 多手机的性能来要求,来对比。不免有些不太合适。
同时联想到前端时间华为发布的 Huawei Mate XT 三折叠手机。一时间网络上的评论两级分化。很多人直呼太贵,有这钱不如去买 iPhone,也有人说三折叠无意义,没有什么实用价值。很多评论都是只站在自己的角度考虑,从未思考这部手机的设计初衷,目标用户。
在展开来看点赞数第二高的评论

一语中的的点出了红米系列产品的最大优点,在以实惠的价格给到了实用的功能,满足简单的需求,真正的考虑到了底层人民的需求。
用户等级分布饼图
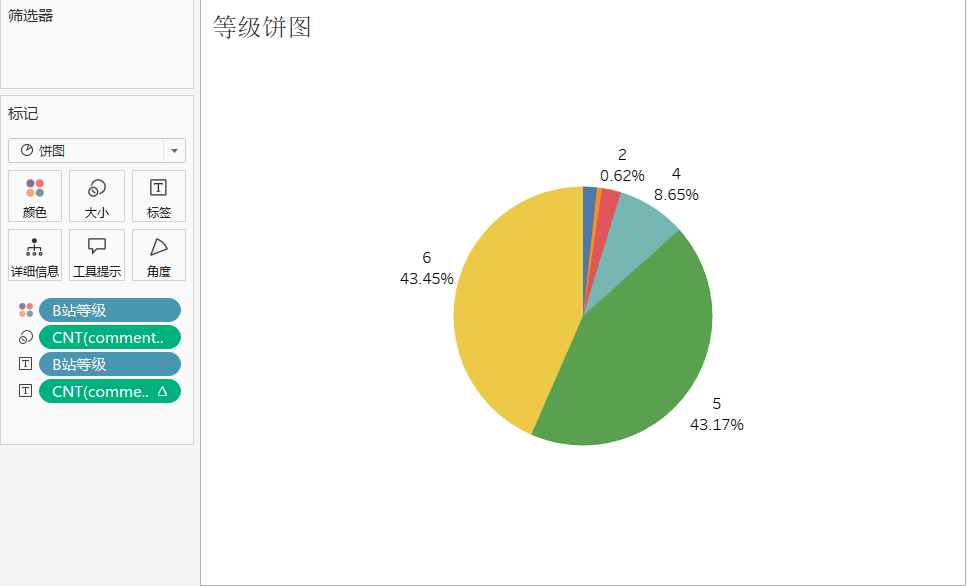
与前面数据统计的结果相同,5 级和 6 级用户占据了评论用户的绝大多数。恐怖如斯,自认为使用 B 站较频繁的我也才只有 4 级。可见数码频道 B 友的恐怖实力!
用户性别分布饼图
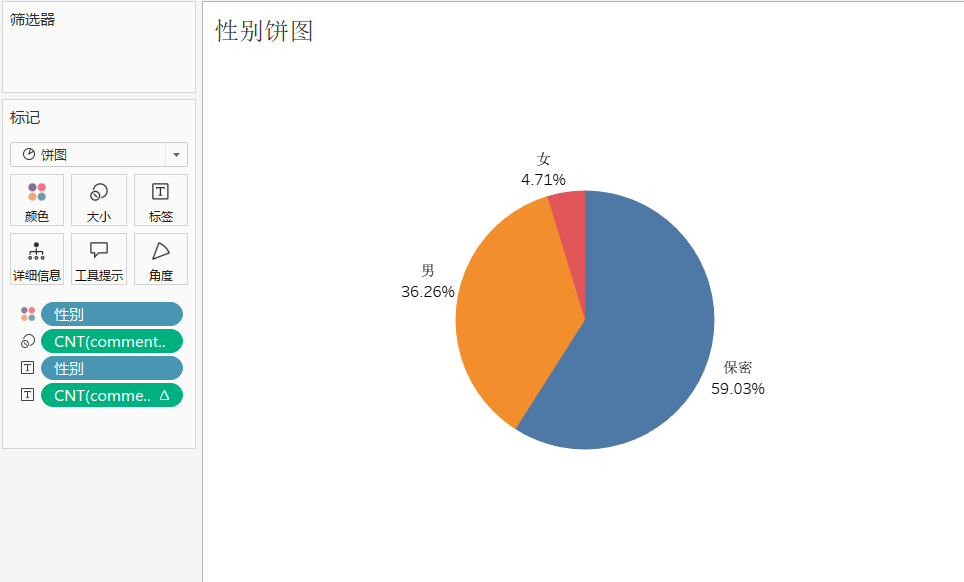
在评论用户信息中中,男性用户占比约 36.26%,女性用户为 4.71%,而选择“保密”性别的用户高达 59.03%。这一数据反映出数码科技内容对男性用户的吸引力较强,特别是在硬件、技术、游戏等领域,男性用户的参与度较高。女性用户的比例较低,可能与数码产品领域的传统受众结构和女性对相关内容的兴趣差异有关。此外,较大比例的“保密”性别用户表明,许多人更注重隐私保护或不希望性别影响评论和互动,反映出平台上性别信息的相对不重要性和用户对内容本身的关注。
IP 属地分布
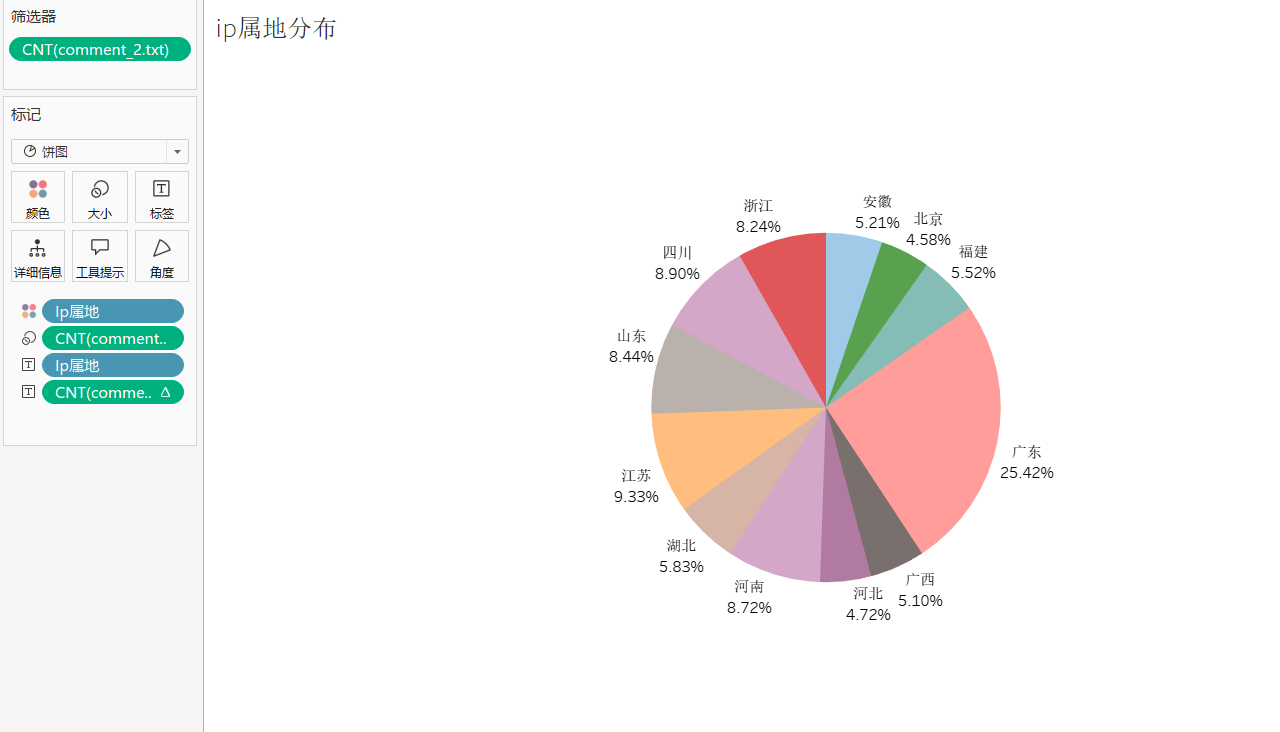
根据图表可以看到,广东省占比最大,江苏占比第二,浙川鲁豫次之。广东作为中国的经济大省,尤其是广州和深圳等城市是数码科技产业的中心。深圳是全球知名的科技创新城市,聚集了大量数码产品的制造商、科技公司和消费者。因此,广东的高占比反映了该地区用户对数码内容的高度关注和参与度。
江浙一带也是经济非常发达的地区,有较强的科技创新和产业基础,信息化程度较高,数码产品的消费市场较为成熟,吸引了较多的当地用户关注和参与数码频道内容。
对于山东河南四川,个人看来很大一方面是人口基数大,对数码产品需求量大,随机科技发展进步,手机进一步普及,市场潜力大,随着信息化水平和科技产业发展,这些地区的数码产品消费将有进一步增长的空间。