

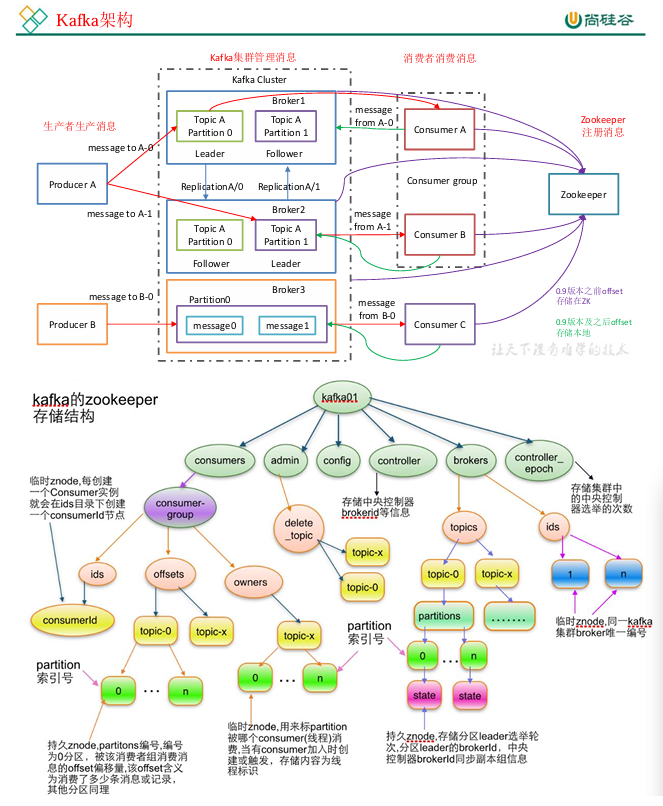
1.1 Kafka 架构总览
Kafka 是一个高吞吐量的分布式消息系统,广泛用于 日志收集、流式数据传输、实时分析 等场景。
核心组成包括:
Producer(生产者):向 Kafka 发送消息
Broker(代理服务器):Kafka 的核心节点,负责接收、存储、分发消息
Consumer(消费者):从 Kafka 拉取并消费消息
Zookeeper(协调服务):管理集群元数据、Broker 注册、Consumer offset 等
🧠 注意:
Zookeeper 中保存 Broker ID、Topic 元信息、Consumer offsets(0.9 之前),
但 不保存生产者信息。
Kafka 架构
1.2 Kafka 机器数量估算
Kafka 集群机器数的经验公式:
机器数量 = 2 * (峰值生产速度 * 副本数 / 100) + 1
📘 示例:
若峰值写入速度为 200 MB/s,副本数为 3
👉 机器数量 = 2 * (200 × 3 / 100) + 1 = 13 台左右
1.3 副本数设置策略
💡 建议:一般企业设为 2,金融等高可靠业务可设为 3。
1.4 Kafka 压测与性能瓶颈
Kafka 官方提供两种压测工具:
kafka-producer-perf-test.sh→ 生产者压测kafka-consumer-perf-test.sh→ 消费者压测
常见性能瓶颈:
网络 I/O (最常见)
Broker 内存
磁盘 I/O
🧩 调优方向:
使用压缩(如
snappy、lz4)提升 batch 大小
优化分区设计
1.5 日志保存与数据量估算
📈 数据估算示例:
每天产生 1 亿条日志,约 100 GB
每条日志 ≈ 1 KB
平均速率:1150 条 / 秒
高峰速率:2300~23000 条 / 秒
每秒传输量:2~20 MB/s
1.6 Kafka 硬盘容量规划
公式:
磁盘大小 = 每日数据量 × 副本数 × 保留天数 / 0.7
示例:
100GB × 2 副本 × 3 天 / 70% ≈ 857 GB(单 Broker)
1.7 Kafka 监控系统
1.8 分区数计算与优化
Kafka 的吞吐量与分区数高度相关。
计算公式:
分区数 = 目标吞吐量 / min(生产者吞吐, 消费者吞吐)
📘 示例:
Producer 吞吐 = 20MB/s
Consumer 吞吐 = 50MB/s
目标总吞吐 = 100MB/s
分区数 = 100 / 20 = 5 个
💡 实际经验值:通常 3~10 个分区较为合理。
1.9 Topic 设计策略
1.10 ISR 副本同步机制
ISR(In-Sync Replicas):同步副本队列,包含 Leader 和所有同步状态的 Follower。
当 Leader 故障时,Kafka 会从 ISR 中选取新的 Leader。
关键参数:
replica.lag.time.max.ms:延迟超过该时间即踢出 ISRKafka 0.10 起移除
replica.lag.max.messages,防止频繁进出队列
1.11 分区分配策略
Kafka 默认提供两种分配策略:
📘 示例:
10 个分区,3 个消费者线程
C1 → 0,1,2,3
C2 → 4,5,6
C3 → 7,8,9
1.12 数据可靠性机制
💡 企业常用配置:
acks = all+retries > 3+enable.idempotence = true
1.13 数据重复与去重策略
Kafka 可能出现重复消息。
常见去重方式:
1.14 数据积压与消费能力不足
📊 常见原因与解决:
1.15 参数优化建议
🔧 Broker 端优化(server.properties)
log.retention.hours=72
default.replication.factor=2
replica.socket.timeout.ms=30000
replica.lag.time.max.ms=600000
🔧 Producer 端优化(producer.properties)
compression.type=lz4
acks=all
batch.size=65536
linger.ms=5
🔧 JVM 内存优化
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"
1.16 高效读写机制
Kafka 高吞吐的三大原因:
分布式 + 分区并行
顺序写磁盘(比随机写快数百倍)
零拷贝技术(Zero Copy)
数据传输路径:
Producer → PageCache → Socket Cache → NIC → Broker
1.17 单条消息大小限制
默认:1 MB
若需更大消息:
replica.fetch.max.bytes=5242880
message.max.bytes=5000000
⚠️ 注意:message.max.bytes 必须 ≤ replica.fetch.max.bytes
1.18 数据清理策略
两种方式:
log.cleanup.policy=compact
1.19 时间点消费(Time-based Offset)
Kafka 支持从指定时间点开始消费:
Map<TopicPartition, OffsetAndTimestamp> offsets =
KafkaUtils.fetchOffsetsWithTimestamp(topic, startTime, props);
1.20 消息拉取与顺序性
拉取模式(Pull):消费者主动从 Broker 拉取数据
顺序性:
单分区内:✅ 有序
多分区间:❌ 无序