

一、Flink的诞生背景
在信息化高速发展的当下,数据产出量呈爆发式增长,且数据迭代速度持续加快。用户使用 APP、浏览网站等行为所产生的数据,从生产、传播到最终消费,整条链路的完成时间可缩短至几秒内。
在此背景下,行业核心需求日益明确:若能从数据链路中快速分析、挖掘有价值的信息,将帮助企业在激烈的市场竞争中占据优势。受此需求驱动,各类流处理引擎迅速崛起、百家争鸣(曾有同类流处理产品与 Flink 展开技术竞争),而 Flink 凭借其卓越的性能,最终在流处理领域确立了主导地位。
二、Flink核心定义与定位
2.1 基本定义
Flink 是阿帕奇基金会(Apache)旗下的下一代开源大数据处理引擎,凭借强大的数据处理能力,已成为各大行业(军工、金融、工业、互联网、车企等)搭建实时数据链路的核心基础设施,在国内大数据实时计算领域占据绝对统治地位(国外应用场景暂不涉及)。
三、Flink的核心定位解析(大数据处理引擎+流处理引擎)
Flink 的“大数据处理引擎”定位包含两层核心含义,二者相辅相成、缺一不可,共同构成了 Flink 的核心价值。
3.1 大数据处理引擎
核心定位是“数据处理”,其核心流程为:从指定数据源(如 Kafka、MySQL 等)读取原始数据,通过 Flink 提供的各类计算 API 完成数据清洗、转换、聚合等操作,最终将处理后的结果输出至目标存储介质(如 MySQL、ES、文件系统等)。
同类主流大数据处理引擎包括 Hive、Spark 等,可根据业务场景的不同选择适配的引擎。
3.2 流处理引擎(实时处理引擎)
核心定位是“流处理领域”,其核心特性可通过与批处理(Batch)的对比,更清晰地理解(注:此处“P”指代 Batch,即批处理):
3.3 Flink的批流处理能力说明
Flink 具备批处理与流处理双重能力,但其核心优势集中在流处理领域,批处理能力仍处于持续完善阶段。
在业界主流应用场景中,Flink 主要用于解决实时流处理相关需求,后续学习也将重点围绕流处理展开,较少涉及批处理相关内容。
四、Flink中的数据流定义
Flink 的核心设计理念围绕“数据”展开,其对数据的核心定义为:所有数据的产出、传输、输出全过程,均以“事件流”(Event Stream)的形式存在。
实际应用示例:用户浏览网站、下单购物、点击广告等行为,会随时间先后产生一系列数据,这些数据并非孤立存在,而是以“流”的形式持续生成、传输(如用户每点击一次按钮,就产生一条点击事件数据,多次点击形成连续的数据流)。
4.1 数据流的两种类型
有界流(Bounded Stream):存在明确的数据开始节点与结束节点,本质是一个有限的数据集合。典型案例为离线数仓中的 Hive 表,表中数据有明确的时间范围和数据边界,可清晰定位第一条、最后一条数据的产生时间。
无界流(Unbounded Stream):仅存在数据开始节点,无明确的结束节点,数据会源源不断地产生,需要处理引擎持续进行处理。典型案例为用户实时行为日志(如 Kafka 中的 Topic 数据),数据实时生成、无终止,数据量无法提前预估。
4.2 有界流与无界流的核心关联
Flink 的核心设计理念中,有界流被视为无界流的一种特殊形式,即通过一定规则(通常以时间为划分标准,如每小时、每天)对无界流进行边界划分,从而得到有界流。
关键注意点:有界流与批处理、无界流与流处理之间无强绑定关系,不可混淆:
无界流:既可以进行流处理(常规应用场景),也可以通过 Flink 的窗口计算划分数据边界,实现“伪批处理”。
有界流:既可以进行批处理(常规应用场景,处理性能更优),也可以进行流处理,但在生产环境中,不推荐对有界流进行流处理。
4.3 实时/离线处理作业的定义
实时处理作业:基于无界流进行流处理,核心特点是数据处理延迟低(通常为毫秒级、秒级),可实时响应数据变化。
离线批处理作业:基于有界流进行批处理,核心特点是数据处理延迟较高(通常为小时级、天级),适用于非实时性需求场景。
五、Flink的三大核心应用场景
Flink 的应用场景覆盖大数据处理的多个领域,核心可分为三类,可根据自身业务需求、时效性要求,匹配对应的应用场景,学习过程中需重点掌握。
5.1 数据同步型应用
核心目标:将数据从一个数据库或存储引擎,高效迁移至另一个数据库或存储引擎。根据数据同步的周期和时效性要求,可分为 ETL 应用和 Pipeline 应用,Flink 对两种应用场景均提供完善支持。
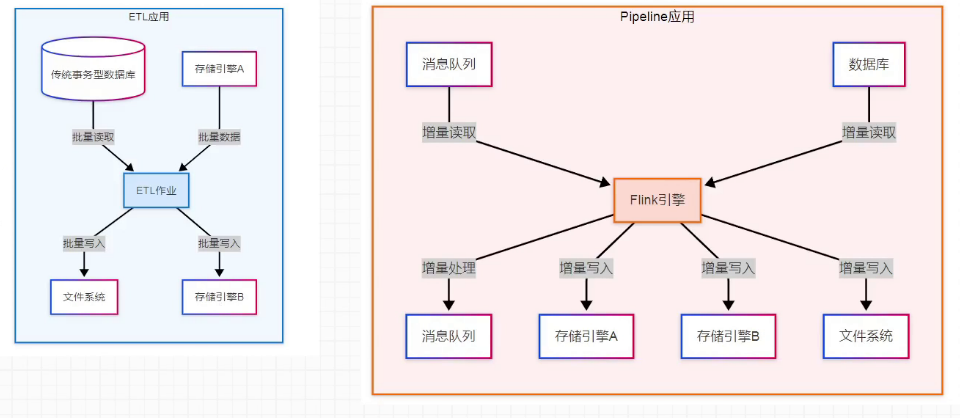
5.1.1 ETL应用
核心特点:采用周期性触发机制(如按小时、按天调度),数据迁移延迟较高,适用于离线数据同步场景。
核心应用场景:
离线数仓构建:将 MySQL、日志服务器等数据源中的原始数据,定时同步至 Hive 数仓的 ODS 层(操作数据存储层),为后续离线数据加工奠定基础。
数据分发:将离线数仓中加工完成的 ADS 层(应用数据服务层)数据,同步至 OLAP 库、KV 存储或报表引擎,供外部业务系统查询、分析使用。
5.1.2 Pipeline应用
核心特点:7×24 小时持续运行,数据迁移延迟低(实时 / 近实时),处理流程与 ETL 一致,均为“读数据→数据处理→写数据”,但无需周期性触发,可实时响应新数据。
核心应用案例:电商网站实时用户行为同步。消费 Kafka 中存储的用户浏览、点击、加购、下单等行为日志,通过 Flink 完成脏数据过滤、字段标准化等处理,将清洗后的有效数据写入 MySQL,供业务系统实时查询用户行为、分析用户偏好。
5.1.3 Flink在数据同步中的优势
Flink 在实时数据同步场景(Pipeline 应用)中优势显著,是业界处理实时数据同步的首选引擎。
简单 Pipeline 需求(约 50% 的场景):可通过 Flink SQL API 结合 UDF(用户自定义函数)快速实现,开发效率高。
复杂 Pipeline 需求:可通过 Flink DataStream API 进行定制化开发,灵活适配各类复杂业务场景。
丰富的内置连接器:Flink 提供了 Kafka、ES、文件系统、MySQL 等多种主流存储引擎的预制连接器,无需手动开发,简单配置即可完成数据读写。
API 关系:Flink Stream API 与 Flink SQL 的关系,类似于 Hadoop 生态中 MapReduce 与 Hive SQL 的关系,前者适用于复杂定制化开发,后者适用于简单查询与处理场景。
5.2 数据分析型应用
核心目标:对海量数据进行分析、挖掘,将分析结果用于报表展示、业务运营决策、风险控制等场景,分为离线数据分析和实时数据分析两类。
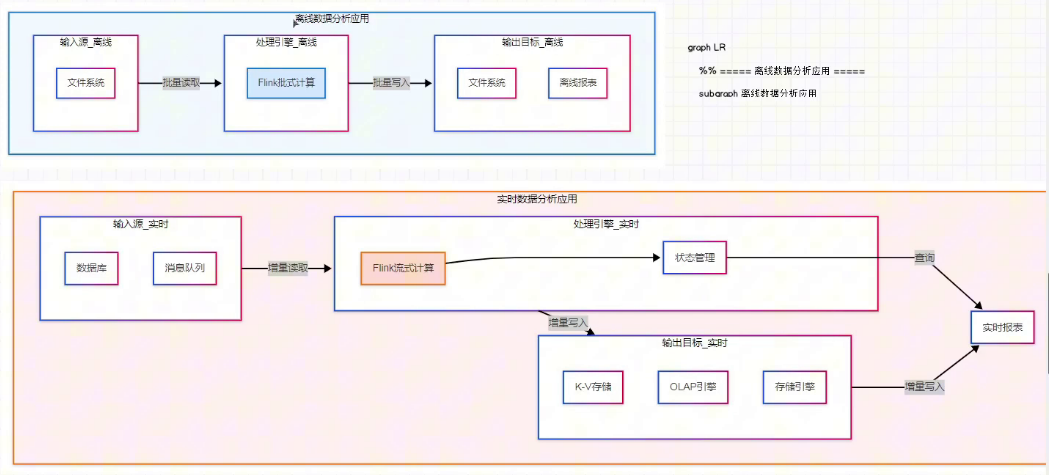
离线数据分析:基于批处理引擎(如 Hive),定期对有界数据进行处理、计算,输出分析结果(如每日经营报表、月度用户画像),处理延迟较高,已无法满足部分业务的实时决策需求。
实时数据分析:接入实时数据流(如 Kafka Topic),通过 Flink 进行持续计算、实时更新分析结果,处理延迟低,可支持实时报表、实时运营调整、实时风险预警等场景:
核心处理流程:实时接入数据源→Flink 实时计算(清洗、聚合、分析)→将结果增量或全量写入外部存储(MySQL、OLAP、KV 存储)或 Flink 状态中。
注意事项:不建议直接查询 Flink 状态获取分析结果,为保障服务稳定性、避免状态异常影响查询,优先从外部存储引擎中读取结果。
5.3 事件驱动型应用
核心定位:有状态的实时应用,通过读取一个或多个事件流中的事件数据,由事件触发计算逻辑、状态更新,或与外部系统进行联动,是最能体现 Flink 高吞吐、低延迟优势的核心应用场景。
5.3.1 与传统事务型应用(后端应用)的对比
5.3.2 关键说明
Flink 的诸多核心特性(如时间定义、窗口机制、状态处理等),均是围绕事件驱动型应用的设计思想进行开发的。
六、学习总结
Flink 的基本定义与定位:Apache 开源大数据处理引擎,是国内大数据实时计算领域的核心基础设施。
Flink 的双重定位:兼具大数据处理引擎(核心为数据处理)与流处理引擎(核心为实时处理)的能力,流处理优势突出。
数据流分类:分为有界流(有限数据)与无界流(无限数据),二者无强绑定批 / 流处理,有界流是无界流的特殊形式。
三大核心应用场景:数据同步(ETL+Pipeline)、数据分析(实时 + 离线)、事件驱动型应用(Flink 核心优势场景)。