

1. 🌈 Spark 基本概念(是什么 & 解决了什么问题)
Apache Spark 是一个适用于大数据环境的 多语言统一计算引擎,支持在:
单机电脑
大规模集群(Hadoop、K8s、Standalone)
云环境(Databricks、EMR 等)
上进行:
批处理(ETL、离线计算)
流处理(近实时)
SQL 查询
机器学习 Pipeline
图计算
相比 Hadoop MapReduce,Spark 主要解决:
MapReduce 磁盘 IO 太多、速度慢
一次作业不能表达多步骤(缺乏 DAG)
编程复杂,不易维护
缺乏丰富生态(流处理、SQL、ML)
Spark 通过 内存计算、DAG 调度、统一 API、强生态,成为目前主流的大数据计算框架。
2. ⚡ Spark 为什么比 Hadoop MapReduce 更快(核心优势)
提升来自四个维度:
2.1 🔥 更快的任务启动时间(Task Startup)
Spark:task 是在 Executor 内 线程级 启动
MR:task 启动一个新的 JVM 进程(非常慢)
➡ Spark 在小任务和 iterative(迭代型)任务中表现远超 MR。
2.2 🔥 更高效的 Shuffle 机制
Shuffle = 分布式系统中最昂贵的操作之一,用于数据重分区。
Spark Shuffle:写磁盘 一次
MR Shuffle:写磁盘 两次(Map 输出、Reduce merge)
➡ 大幅减少磁盘和网络 IO
2.3 🔥 DAG + Pipeline(流水线执行,避免中间落盘)
MapReduce 每一步任务必须:
MR → HDFS → MR → HDFS → MR…
Spark 会根据用户代码自动构建 DAG 图:
RDD/DataFrame → Stage1 → Stage2 → Stage3
中间 steps 无需写入 HDFS
(除 shuffle 阶段)
➡ 执行更快
➡ 资源开销小
➡ 适合复杂计算链路
2.4 🔥 内存缓存机制(Cache / Persist)
Spark 可以将数据缓存到:
内存(Memory)
磁盘(Disk)
熔合格式(如 DataFrame columnar cache)
特别适合:
迭代计算(机器学习)
多次复用的维表 / 中间表
3. ⭐ Spark 核心特点总结(必须掌握)
4. 🏛️ Spark 架构深度理解(Driver、Executor、Cluster Manager)
Spark 典型架构如下:
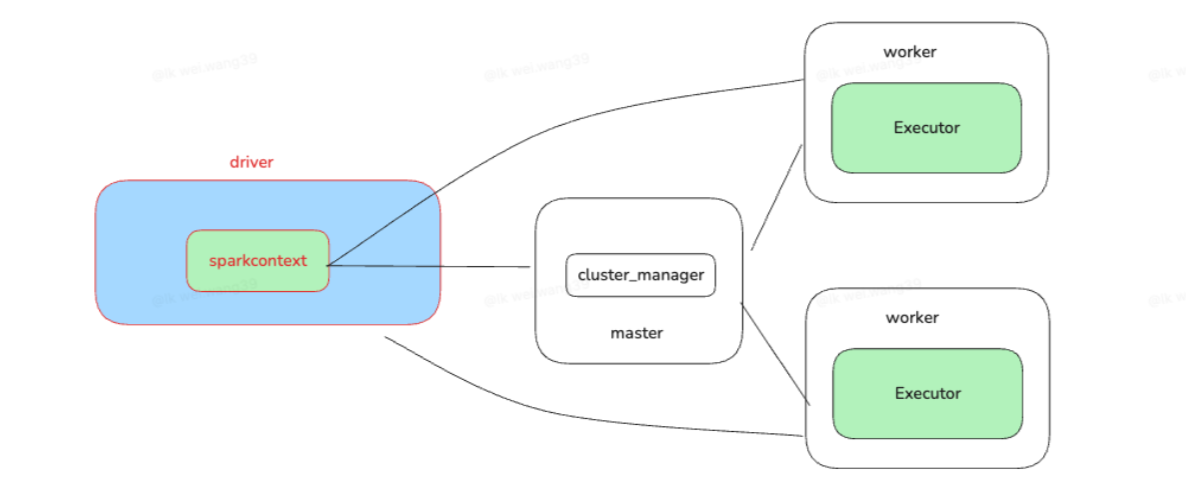
4.1 ✨ Driver(驱动器)
Driver 是 Spark 任务的大脑,职责包括:
解析用户程序
生成 RDD DAG
进行 Stage 划分
向 Executor 分发 Task
监控任务运行
处理失败重试
Driver 稳定性非常关键;在生产环境中:
YARN cluster 模式:Driver 在 worker 节点
YARN client 模式:Driver 在提交任务的客户端
4.2 ✨ SparkContext(上下文)
SparkContext 是:
Spark 作业的生命周期管理者
Cluster Manager 通信的入口
负责创建 RDD、广播变量、累加器
4.3 ✨ Master(集群管理器)
可能是:
Spark Standalone Master
Hadoop YARN ResourceManager
Kubernetes API Server
负责:
分配资源
管理 Worker 心跳
调度 Executor
4.4 ✨ Worker(工作节点)
每个 Worker 会:
接收 Master 的任务
启动多个 Executor
管理 Executor 的生命周期
4.5 ✨ Executor(执行器)
是 task 的执行单元,它负责:
执行真正的代码
分配线程(执行 task)
存储缓存的数据(RDD cache)
执行 shuffle 读写
不同 Executor 之间 互不共享内存。
5. 🌐 Spark 生态组件(全套能力)
6. 🖥️ Spark 运行模式(部署方式详解)
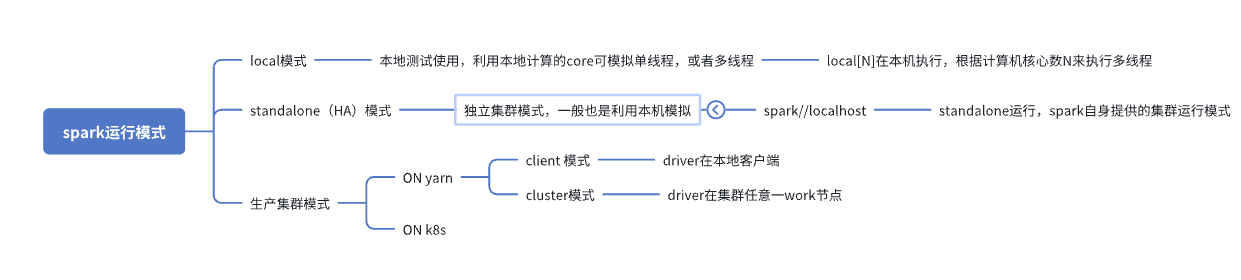
6.1 🧪 Local 模式(开发使用)
不需要集群
可设置线程数
示例:
local(单线程)local[4](4 个线程)local[*](使用所有 CPU 核心)
用途:
学习、调试
单机快速测试 ETL 或 SQL
6.2 🔒 Standalone 模式(Spark 自带)
Spark 自带的 mini 集群调度器
支持主备 HA
简单、稳定,适合:
小团队集群
测试环境
教学实验平台
6.3 🧱 YARN 模式(最常用的生产模式)
是目前企业生产最广泛的 Spark 运行模式。
含两种运行方式:
✔ Client 模式
Driver 在客户端机器:
日志输出到本地
适合交互式任务(notebook)
✔ Cluster 模式
Driver 在 YARN 某个节点上:
更稳定
提交任务后无需保持客户端在线
➡ 生产 ETL 任务首选
6.4 ☸ Kubernetes 模式(云原生趋势)
优势:
完整容器化部署
自动扩缩容
火焰图监控更强
云平台适配更好(Databricks、EMR on EKS)
适合:
动态计算资源
多租户隔离
云原生数据平台