

🌐 常用端口号
⚙️ Hadoop 配置文件说明
🧩 core-site.xml:Hadoop 核心配置(如默认文件系统 URI、I/O 参数等)。
💾 hdfs-site.xml:HDFS 存储配置(副本数、Block 大小、权限校验等)。
🔄 mapred-site.xml:MapReduce 任务运行参数(Job 框架、JVM 配置等)。
🧠 yarn-site.xml:YARN 资源调度配置(内存、CPU、队列、节点管理等)。
👷♂️ workers:记录所有 DataNode 主机名列表。
✍️ HDFS 写文件流程

以副本数为 3 为例,说明一个文件从客户端上传到 HDFS 的全过程。
🧩 1. 客户端请求上传
客户端(Client)通过
DistributedFileSystem向 NameNode 发起写入请求。NameNode 检查:
文件是否已存在;
目标目录是否存在;
权限是否满足要求。
若检查通过,NameNode 回复“允许上传”,否则返回错误信息,终止操作。
📦 2. NameNode 分配存储节点
客户端将文件切分为一个或多个 Block(默认 128MB)。
客户端向 NameNode 请求第一个 Block 的存储位置。
NameNode 根据机架感知策略(Rack Awareness)返回三个 DataNode:
第一个副本放在本地节点(或同机架);
第二个副本放在不同机架;
第三个副本与第二个同机架但不同节点。
🔗 3. 建立数据传输管道
客户端通过
FSDataOutputStream与第一个 DataNode(DN1)建立连接;DN1 再与 DN2 建立连接,DN2 再与 DN3 建立连接;
管道顺序为:
Client → DN1 → DN2 → DN3;每个节点都会返回握手确认,最终形成稳定的传输通道。
📤 4. 数据写入与确认
客户端开始以 Packet(数据包) 为单位写入数据:
每个 Packet 会依次经过 DN1 → DN2 → DN3;
DN3 写入本地磁盘后返回确认;
DN2 收到 DN3 的确认后再回复 DN1;
DN1 收到确认后再通知客户端;
客户端才认为该 Packet 写入成功。
若某个 DataNode 写入失败,NameNode 会重新分配新的节点存储该副本。
🔁 5. 后续 Block 写入
一个 Block 写满后,客户端会再次向 NameNode 请求下一个 Block 的存储节点;
继续建立管道、传输数据;
所有 Block 均写入成功后:
客户端关闭流;
NameNode 更新元数据(文件名、Block 信息、副本位置等)。
✅ 写入完成
最终,NameNode 持久化该文件的元数据;
DataNode 存储文件的物理数据块。
HDFS 写入流程至此结束。
📖 HDFS 读文件流程
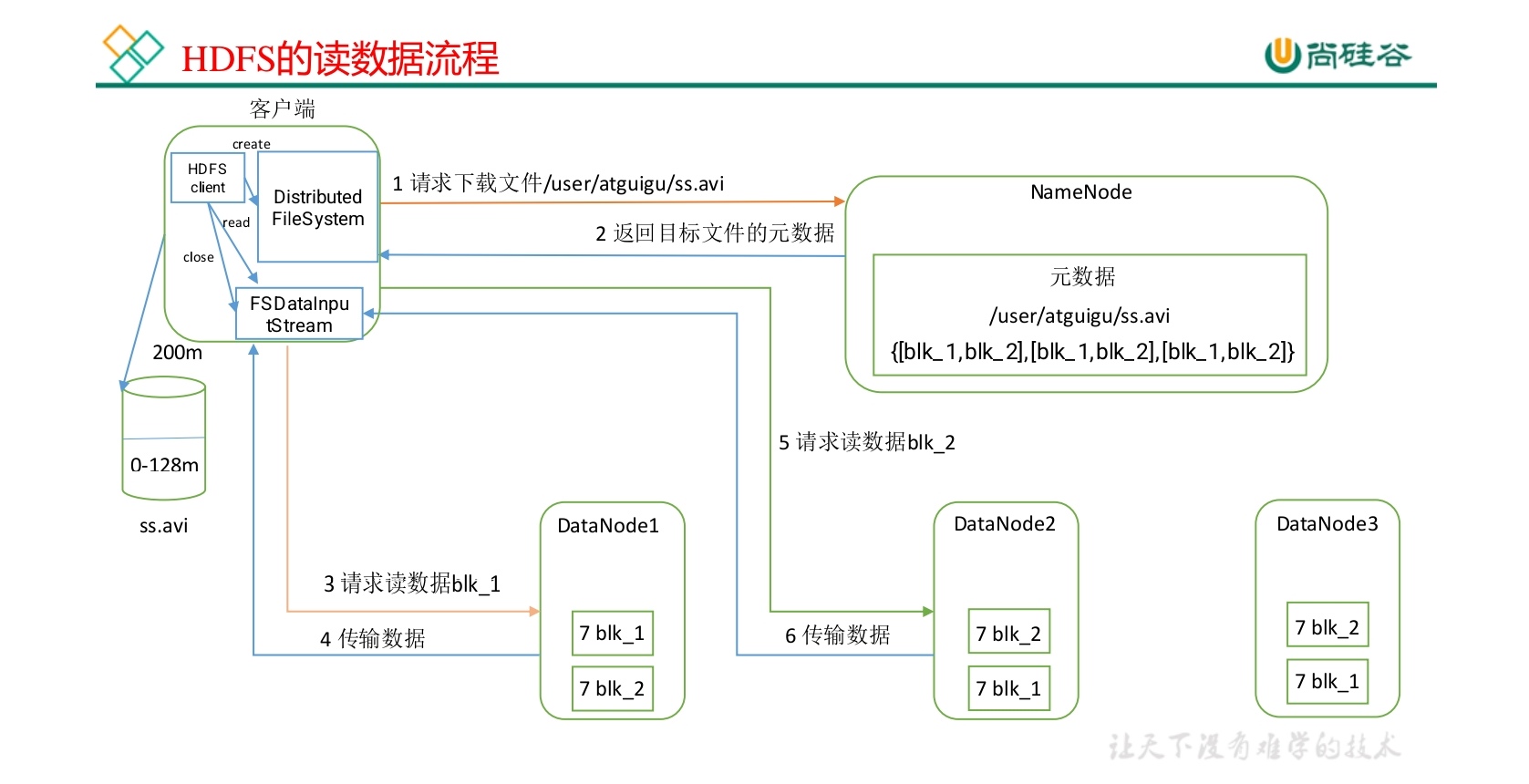
以客户端读取一个多块文件为例,说明完整的读取与容错机制。
📬 1. 客户端发起读取请求
客户端通过
DistributedFileSystem调用 open() 方法;向 NameNode 请求目标文件的 Block 列表;
NameNode 返回:
每个 Block 对应的副本所在的 DataNode;
每个节点的网络拓扑信息(机架、距离等)。
🗺️ 2. NameNode 排序副本位置
NameNode 会计算客户端与各个 DataNode 的距离;
按“近到远”排序返回副本列表;
优先选择同机节点;
若无,再选择同机架节点;
最后选择跨机架节点;
这样可最大化读取速度、减少网络传输延迟。
💾 3. 建立输入流与数据读取
客户端获得
FSDataInputStream(底层封装DFSInputStream);DFSInputStream自动选择最近的 DataNode;客户端调用 read() 方法开始读取:
读取数据块(Block)中的数据流;
读取到内存缓冲区后交付给应用层;
读取完当前 Block 后自动关闭连接。
🔄 4. 容错与副本切换机制
如果当前 DataNode 读取失败:
客户端会自动切换到下一个最近的副本节点;
同时通知 NameNode 标记该副本为失效;
后续由 NameNode 触发副本修复机制。
🧱 5. 连续读取多个 Block
若文件由多个 Block 构成:
当前 Block 读取完后,
DFSInputStream向 NameNode 请求下一批 Block;按照就近原则重复读取;
所有 Block 依次读取后,在客户端侧合并为完整文件。
✅ 6. 关闭连接与清理资源
全部数据读取完毕;
客户端关闭输入流;
HDFS 自动释放连接和缓存资源。
🧩 HDFS 小文件问题与优化方案
❗ 小文件的危害
每个文件或 Block 在 NameNode 占用约 150 字节元数据内存;
小文件过多会导致:
NameNode 内存膨胀;
GC 频繁;
RPC 响应延迟;
文件系统操作效率显著下降。
💡 举例:
128GB 内存能容纳约 9 亿个文件块(128×1024³ ÷ 150 ≈ 9×10⁸)。
✅ 解决方案
📚 HAR 归档(Hadoop Archive)
将多个小文件封装为一个
.har文件;减少 NameNode 元数据数量;
适合长期存放、只读数据。
🧩 CombineTextInputFormat
在 MapReduce 输入阶段合并多个小文件为一个 Split;
提高并行度与处理效率。
♻️ JVM 重用机制
避免为每个小文件启动新的 JVM 实例;
可在
mapred-site.xml配置:<property> <name>mapreduce.job.jvm.numtasks</name> <value>10</value> <description>Number of tasks to run per JVM (-1 = unlimited)</description> </property>⚠️ 若无小文件场景,请勿开启,否则会占用 Task 槽资源。
🧭 HDFS 读写流程总结表
💬 HDFS 常见面试问答小结
🧱 一、HDFS 架构与核心组件
1️⃣ HDFS 主要由哪几个核心组件组成?它们各自的职责是什么?
2️⃣ NameNode 和 Secondary NameNode 的区别?
📂 二、HDFS 的高可靠性机制
1️⃣ HDFS 如何保证数据可靠?
✅ 三副本机制
默认每个 Block 保存 3 份副本:
一份在本地节点;
一份在其他机架;
一份在同机架不同节点。
NameNode 负责管理副本位置,防止集中风险。
✅ 心跳检测机制
DataNode 定期向 NameNode 发送心跳包;
若心跳超时(默认 10 分钟),NameNode 判定该节点失效并重新复制数据。
✅ 管道式写入 + 确认机制
写入时多级确认(DN3→DN2→DN1→Client);
任一 DataNode 异常会触发副本重建。
2️⃣ 若某个 DataNode 宕机,HDFS 如何恢复数据?
NameNode 检测到心跳超时后,标记节点失效;
触发“副本复制”任务,将丢失的 Block 从其他健康节点复制到新的 DataNode;
副本数恢复到预设值(默认 3)。
🧩 三、HDFS 读写机制与优化
1️⃣ HDFS 为什么采用“大块存储”?
默认 Block 大小为 128MB(或 256MB);
优点:
减少寻址次数;
降低 NameNode 元数据压力;
提高顺序读写性能;
缺点:
不适合大量小文件场景(NameNode 内存膨胀)。
2️⃣ 为什么说 HDFS 不适合存小文件?
每个文件(或 Block)会在 NameNode 内存中存一份元数据(约 150 字节);
小文件过多 ⇒ 元数据爆炸 ⇒ NameNode 内存占满 ⇒ 性能严重下降。
🧭 优化策略:
使用 HAR 文件归档;
使用 CombineTextInputFormat;
合理开启 JVM 重用。
3️⃣ 写入数据时,为什么使用“流水线写入(Pipeline)”?
优点:
数据副本可同时分发;
传输效率高;
实现分布式并行写入;
原理:
Client → DN1 → DN2 → DN3;
多节点并发确认,减少延迟;
任一 DN 失败会触发副本重新分配。
4️⃣ HDFS 的读操作为什么更倾向于“就近读取”?
NameNode 在返回副本列表时会按“距离”排序(Rack Awareness);
选择离客户端最近的节点读取数据;
目的:
减少跨机架网络传输;
提升吞吐量;
提高容错性。
🧠 四、HDFS 的一致性与安全性
1️⃣ HDFS 如何保证数据一致性?
HDFS 提供 “一次写入,多次读取”(Write Once, Read Many)模型;
文件一旦写入完成不可修改;
避免并发修改带来的不一致问题;
所有修改均通过 NameNode 统一管理。
2️⃣ 如何防止误删或误操作?
可开启 Trash(回收站)机制;
删除文件时先进入
.Trash目录;超过设定时间后自动清理;
相关配置:
<property> <name>fs.trash.interval</name> <value>1440</value> <!-- 保留时间:分钟 --> </property>
📊 五、性能与调优要点
🧭 面试速记总结(一句话版本)
HDFS = 分布式文件系统 + 高可靠 + 高吞吐 + 一次写入多次读取。
NameNode 管元数据,DataNode 存实际数据。
写入数据走管道、读取数据就近访问。
小文件伤内存,大文件爱吞吐。
高可靠靠副本,数据一致靠单点写入。