

选择合适的 Hive 文件格式,能够显著提升查询性能、存储效率和计算资源利用率。Hive 支持多种存储格式,包括 TextFile、ORC、Parquet、SequenceFile 等。其中 ORC、Parquet 属于列式存储,性能最佳。
1. Hive 文件格式概述
Hive 的存储格式影响:
数据读取量
查询性能
压缩率
Schema 管理机制
与外部引擎的兼容性(Spark / Presto / Flink)
常用格式:
TextFile(默认)、ORC、Parquet、SequenceFile
2.文件格式详解
2.1 Text File
TextFile 是 Hive 默认的数据文件格式。
文件中的每一行对应 Hive 表的一行记录。
✔ 建表示例
create table textfile_table (
column_specs
)
stored as textfile;
✔ 特点
易读易写,兼容性好
适合简单数据存储
无压缩效率、无列存储优势
多用于数据源输入、日志型数据
2.2 ORC 文件格式(重点 ⭐)
1)简介
ORC(Optimized Row Columnar)是 Hive 专用的列式存储格式,支持:
高效压缩(ZLIB/Snappy)
Predicate pushdown(谓词下推)
索引(Index)
列编码(Column Encoding)
跳跃读取(Skip read)
适合 Hive 场景的首选格式。
2)行式 vs 列式存储对比
3)ORC 文件结构
ORC 文件由以下部分组成:
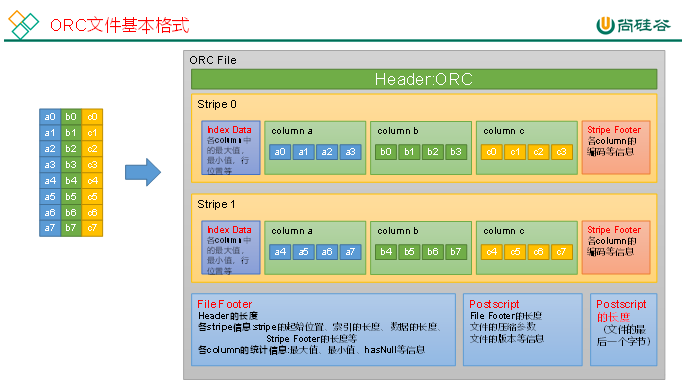
读取顺序是 从尾部开始解析(先读 PostScript → File Footer → Stripe 信息)。
4)建表语句
create table orc_table (
column_specs
)
stored as orc
tblproperties (
"orc.compress"="snappy"
);
5)常用 ORC 参数
2.3 Parquet 文件格式
Parquet 是 Hadoop 生态中广泛使用的列式存储格式,特别适用于 Spark、Presto、Flink 等系统,是一种更通用的格式。
1)Parquet 文件结构
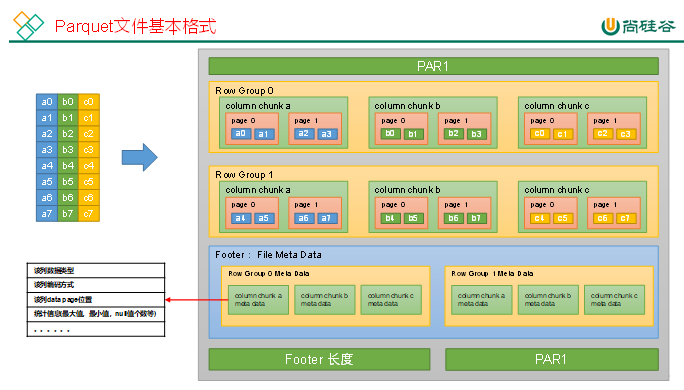
关键概念:
Row Group:多个行组成一个 RG(通常与 HDFS block 对齐)
Column Chunk:Row Group 中的单列数据
Page:列块中的最小存储单元
2)建表语句
create table parquet_table (
column_specs
)
stored as parquet
tblproperties ("parquet.compression"="snappy");
3)Parquet 配置参数
3. Hive 压缩机制
Hive 支持 文件压缩 和 计算过程(MR Shuffle)压缩。
合理使用压缩可以显著提升:
数据扫描速度
网络 IO 效率
磁盘利用率
3.1 文件级压缩
不同文件格式的压缩方式如下:
✔ 1)TextFile 压缩
不需要建表声明,只需将压缩文件导入即可。
查询时 Hive 会自动解压。
写入数据时需设置:
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
✔ 2)ORC 压缩(建表设置)
create table orc_table (
column_specs
)
stored as orc
tblproperties("orc.compress"="snappy");
✔ 3)Parquet 压缩(建表设置)
create table parquet_table (
column_specs
)
stored as parquet
tblproperties("parquet.compression"="snappy");
3.2 计算过程压缩(MR 阶段)
✔ 1)Mapper 输出中间数据压缩(Shuffle 前)
减少网络 IO:
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
✔ 2)Hive SQL 中间 MR 结果压缩
两个 MR 阶段之间的临时数据压缩:
set hive.exec.compress.intermediate=true;
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;