

Shuffle 是 Spark 性能调优、底层理解、面试问答中最核心、最难理解的部分之一。
可以说:
理解 Shuffle = 理解分布式计算的本质。
以下内容将从概念 → 原理 → 执行流程 → 演化历史 → 性能瓶颈 → 优化方法,进行完整系统讲解。
1. 🌈 什么是 Shuffle?
从本质上讲:
👉 Shuffle = 数据在集群节点之间重新分布 + 排序 + 分组 + 合并
它通常发生在以下场景:
不同分区的数据需要按 key 聚合(reduceByKey / groupByKey)
排序(sortByKey)
Join(根据 key 进行匹配)
重分区(repartition)
去重(distinct)
简单理解:
Shuffle 是让“相同 key 的数据汇聚到一起”的过程,因此必须跨节点通信。
2. 🎯 Shuffle 为什么如此重要?
Shuffle 是 Spark 中最昂贵的阶段,是性能瓶颈出现的主要原因,因为它涉及:
磁盘写入(spill)
磁盘读取(merge)
网络传输(shuffle read)
序列化 / 反序列化
排序和哈希运算
内存分配与 GC
因此:
一个 Spark 作业是否快,往往取决于 Shuffle。
3. 🧱 Shuffle 触发条件(宽依赖)
在 RDD 的依赖中:
窄依赖:父 RDD 的一个分区只被一个子 RDD 分区使用 → 不会产生 Shuffle
宽依赖:父 RDD 的一个分区可能被多个子 RDD 分区使用 → 必然 Shuffle
典型会产生 Shuffle 的算子:
reduceByKey(聚合)
groupByKey(分组)
sortByKey(排序)
join(关联)
repartition(重分区)
distinct(去重)
coalesce(shuffle = true 时)
4. ⚙ Shuffle 与 Stage 的关系
Spark 中:
Action 算子 → Job 划分
Shuffle → Stage 划分
也就是说,每次遇到宽依赖(Shuffle),当前 Stage 就会“断开”,重新开启下一阶段。
例如:
map → reduceByKey → map → sortByKey → collect
这个流程中有两个 Shuffle,因此至少 3 个 Stage。
5. ⛓ 回顾 MapReduce 中的 Shuffle
为了理解 Spark Shuffle,必须先记住 MR Shuffle 的关键流程:
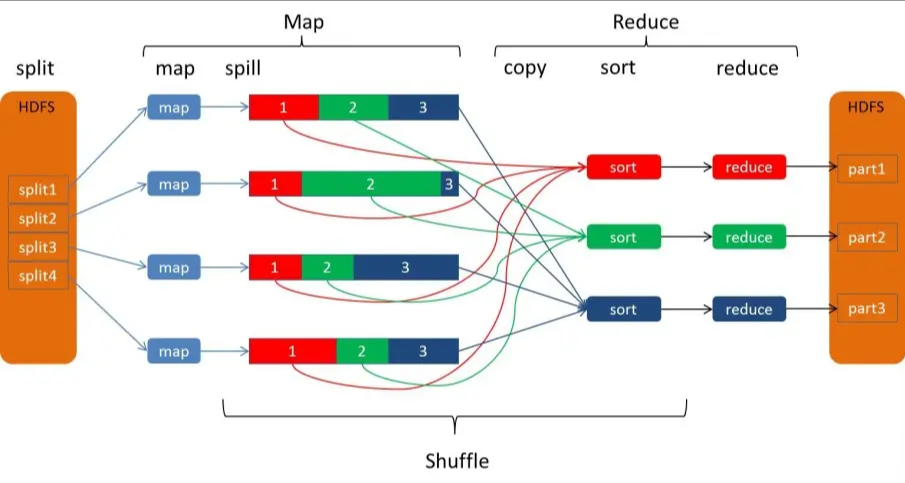
MR Shuffle 过程:
Map 读取数据生成 KV
KV 写入环形缓冲区
缓冲区满 → 溢写到磁盘(可能多次)
多个溢写文件进行归并排序(merge)
Reduce 端从所有 Map 拉取数据
Reduce 对数据进行最终合并处理
特点:
多次溢写
多次 merge
文件数量庞大
强依赖磁盘
Spark 正是在此基础之上做了大量优化。
6. 🚀 Spark Shuffle 的演进史
Shuffle 在 Spark 中经历了 3 次重要演进:
🥇 阶段 1:Hash Shuffle(已淘汰)
特点:
每个 Map Task 为每个 Reduce Task 生成一个小文件
→ 文件数 = Map 数 × Reduce 数(文件爆炸)
缺点:
文件过多
IO 成本极高
不支持排序
被弃用是必然结局。
🥈 阶段 2:Sort Shuffle(引入排序合并机制)
为了解决“小文件爆炸”问题,引入 Sort-Based Shuffle:
Map 阶段先排序后写文件
多次溢写文件会 merge 成单个文件
引入 index 文件
更稳定、更可控。
🥇 阶段 3:Tungsten Sort Shuffle(当前默认)
Spark 2.x 后全面使用:
Sort-Based Shuffle
结合 Tungsten 内存管理(off-heap)
使用二进制格式存储数据(减少对象开销)
最终每个 Map Task 只生成 1 个数据文件 + 1 个索引文件
这是目前最可靠、最强的 Shuffle 实现方式。
7. 🧩 Sort-Based Shuffle 工作原理
Sort Shuffle 分成两个部分:
Shuffle Write(map 阶段)
Shuffle Read(reduce 阶段)
下面详细分析全过程。
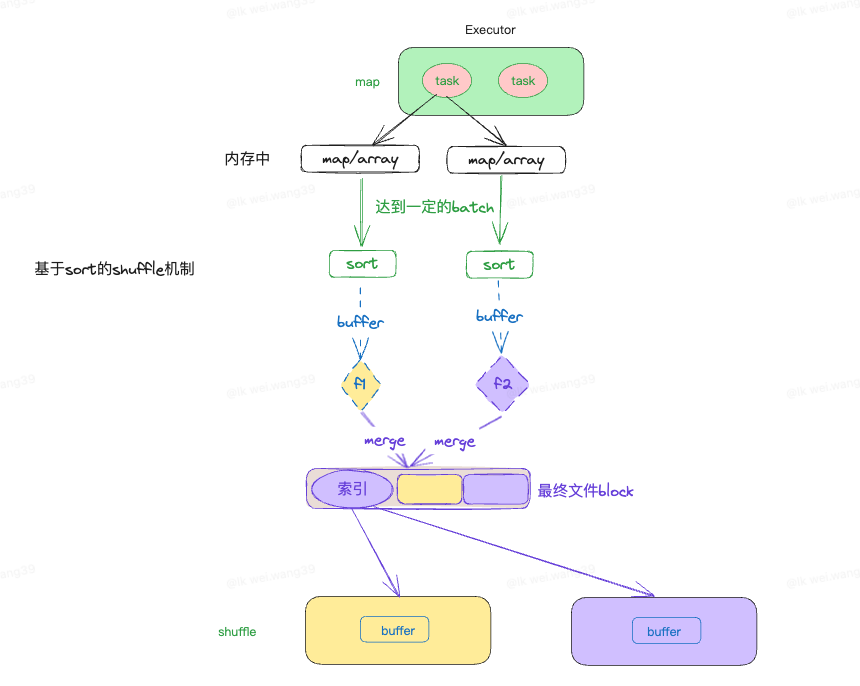
7.1 ✍ Shuffle Write(Map 端流程)
第一步:数据写入内存结构
Spark 会根据算子选不同数据结构:
reduceByKey → HashMap(需要聚合)
groupByKey → ArrayBuffer(只分组)
join → 特殊结构维护 key → records 映射
第二步:内存达到阈值 → 溢写(spill)到磁盘
当内存缓冲区达到阈值:
对数据进行排序(按 key 或 partition)
写入磁盘生成溢写文件
清空缓冲区
再次读取下一批数据
由于可能产生 多个溢写文件,后续需要合并。
第三步:对所有溢写文件进行最终 Merge
合并后生成:
最终数据文件(按分区顺序记录数据)
index 文件(记录每个 reduce 拉取数据的位置段 offset)
这一点极其关键!
👉 Sort Shuffle = 每个 Map Task 只生成 1 个文件
这是 Spark 中 Shuffle 能支撑大规模集群的核心。
7.2 🔄 Shuffle Read(Reduce 端流程)
Reduce Task 的流程如下:
向所有 Map 端节点请求 index 文件中的自己对应的分段数据
拉取数据(网络通信,可能大量数据)
对拉取的数据进行 merge / sort
执行聚合、排序等逻辑
输出最终结果
Reduce 端往往是整个 Shuffle 阶段最耗时的地方。
8. 🌀 Bypass Merge 机制(Shuffle 的小优化)
这是 Sort Shuffle 的一个特例,用来优化“小规模 shuffle 场景”。
触发条件:
Map Task 数量 < spark.shuffle.sort.bypassMergeThreshold(默认 200)
不能是聚合类算子
例如 reduceByKey 会聚合 → 无法 bypass
特点:
不进行排序
走 Hash 逻辑分桶
最后生成单一文件
适合:
repartition(10)
groupByKey(小规模)
小表 shuffle
9. 📚 三种 Shuffle 的对比总结表
🔥 Tungsten Sort Shuffle = Spark 官方最终形态
10. 💣 Shuffle 常见性能瓶颈
Shuffle 会导致:
大量网络传输(反压、阻塞)
大量磁盘写入(spill、merge)
大量磁盘读取(shuffle fetch)
大量序列化 / 反序列化
大量对象创建导致 GC
数据倾斜导致任务长尾
Shuffle 是 Spark 性能问题的最大来源。
11. 🛠 Shuffle 优化方向(生产必备,面试必问)
11.1 算子优化
使用 reduceByKey 代替 groupByKey
groupByKey → 会拉取所有 value(数据量巨大)
reduceByKey → map 端本地聚合减少数据量使用 map-side combine(预聚合)
11.2 分区优化
使用 repartition / coalesce 合理调整分区
避免分区数过多(网络连接指数级增长)
11.3 数据倾斜优化
使用随机前缀法(salting)
使用两阶段聚合
broadcast join 小表
自定义分区器
11.4 内存与溢写优化
调整:
spark.memory.fraction
spark.shuffle.file.buffer
spark.shuffle.spill.compress
spark.shuffle.compress
减少溢写 + 减少磁盘 IO = 显著提升 Shuffle 性能。
12. 🏁 Shuffle 总结
Shuffle = 网络 + 排序 + 磁盘 + 合并
Shuffle 触发宽依赖,决定 Stage 分界
Hash Shuffle 已淘汰
Sort Shuffle 每个 map 只产生一个文件
Tungsten Shuffle 是当前最强 Shuffle
Bypass 机制在任务少时优化
Shuffle 是 Spark 性能瓶颈
常见优化点:预聚合、减少分区、处理倾斜、优化内存、参数调优