

Spark 作为典型的 内存计算框架,其性能高度依赖内存管理机制。
Executor 是实际执行 Task 的核心单元,因此 Spark 的内存模型主要围绕 Executor 端 JVM 内存 展开。
Spark 内存经历过两代模型:
静态内存管理(Spark 1.6 之前)
统一内存管理 / 动态内存管理(Spark 1.6 之后,默认)
Spark 内存模型基础
🧠 为什么 Spark 强依赖内存?
Spark 中:
Task 执行计算(如 shuffle、聚合、join)需要执行内存
RDD/DataFrame 缓存 需要存储内存
内存不足可能导致
频繁 GC
Shuffle spill(落盘)
Out Of Memory 错误
性能大幅下降
因此 Spark 必须设计一套 高效的内存分配机制。
Executor 进程内存分布概览
Executor 是 JVM 进程,其内存大体分为:
🗄️ 堆内内存(In-Heap Memory)
存储 JVM 对象
由 JVM GC 管理
主要用于:RDD 数据、执行内存数据结构、Shuffle 内部对象
📦 堆外内存(Off-Heap Memory)
不受 JVM GC 管理
Spark 通过 Unsafe API / Netty 手动管理
主要用于:
Tungsten 内部的二进制存储
Shuffle 数据
内存列式缓存
堆外内存能减少 GC 频率,提高大数据任务性能。
✨ 静态内存管理(Spark 1.6 之前)
这是 Spark 最早的内存管理模型,特点是 固定比例、无法动态调节,在任务特性较复杂的场景下会造成大量资源浪费。
🔧 静态内存整体结构
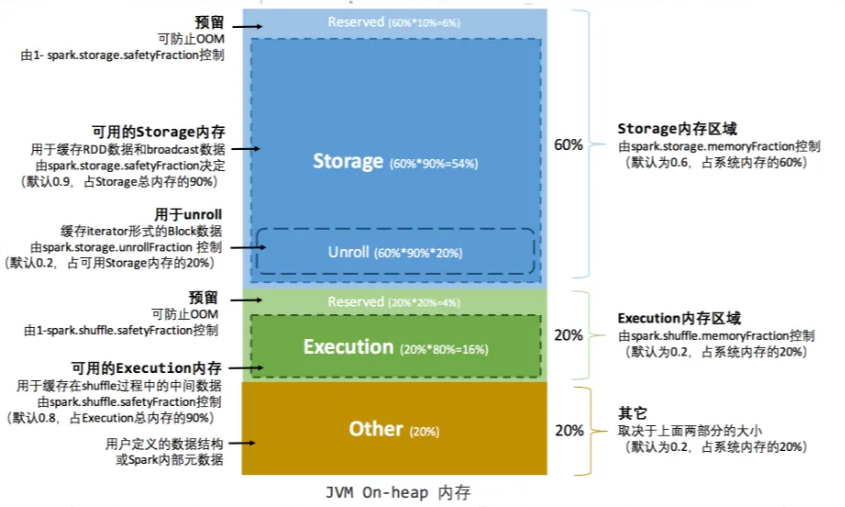
Executor 堆内内存被划为 3 大部分(固定比例):
🎯 补充:Unroll Memory
RDD 缓存过程中,为将数据从计算状态转换为缓存状态,需要临时占用内存,此过程为 unroll,由 Storage 管理。
📌 静态内存管理的主要参数
spark.storage.memoryFraction(默认 0.6)
控制 Storage 内存占比spark.shuffle.memoryFraction(默认 0.2)
控制 Execution(Shuffle)内存占比
堆外内存固定约 380MB,不可变。
👍 静态模型优点
内存规划简单、结构明确
在任务结构稳定时表现可预测
👎 静态模型缺点(被淘汰的根本原因)
① 固定比例导致资源浪费
Storage 空闲、Execution 紧张 → 无法互相借内存
→ 造成频繁 spill,性能急剧下降
② 无法适配不同任务的内存需求
任务类型多样:
有的计算密集
有的缓存密集
固定比例会导致资源失衡
③ 调优困难
只能靠修改 JVM 内存参数、调比例 → 成本极高
因此 Spark 在 1.6 之后正式采用 统一内存管理模型。
✨ 统一内存管理(Spark 1.6+ 默认)
为解决静态模型的缺陷,Spark 引入了 动态共享机制,让 Storage 和 Execution 可以互相借用内存,大幅提升灵活性与性能。
🔧 统一内存整体架构

Executor 内存被分成两大部分:
可用内存中:
Storage 默认可用:50%
Execution 默认可用:50%
🔄 动态共享机制(核心机制)
🟢 Storage 空闲 → Execution 可以“抢占”
大量 shuffle 时,Execution 能借用 Storage 的空闲空间。
🟣 Execution 空闲 → Storage 可以扩容
需要缓存大量数据时,可用内存不足 → Storage 自动扩容。
不过有一条 不对称规则:
这是为了保证任务执行不会因内存不足而失败。
📦 堆外内存在统一内存中的角色
堆外内存和静态时代一致:
主要服务于 Tungsten、Shuffle、序列化等
减少 GC 参与,提高性能
更适合大规模数据处理
✨ 静态内存管理 vs 统一内存管理(对比总结)
统一内存管理对性能提升极其明显,是 Spark 默认推荐的方案。
✨ 工作中常用 Spark 内存调优建议
🎯 资源配置建议
Executor 资源:
CPU : Memory = 1 : 3 或 1 : 4(常用经验值)内存不能盲目扩大:会导致 GC 压力 ↑
内存过小:spill ↑,性能下降明显
🎯 重要调优参数
--num-executors:执行并行度--executor-memory:单节点内存--executor-cores:每个 Executor 并发度--driver-memory:Driver 内存spark.sql.adaptive.enabled=true:开启自适应执行(推荐)