

NameNode 是 HDFS 的核心组件,负责管理整个文件系统的元数据。在早期 Hadoop1.x 中,NameNode 是单点节点,因此其可靠性和可用性直接决定了整个集群是否能正常运行。
Hadoop2.x 引入 HA(高可用)机制,通过主备 NN 架构解决单点问题,并提供更好的容错能力与系统稳定性。
1. 为什么需要 NN 的 HA?
在 Hadoop1.x 的架构中,NameNode 承担以下关键任务:
维护文件系统的目录结构(元数据)
接收客户端请求
与 DataNode 进行心跳检测
处理读写操作的元数据更新
问题:只有一台 NameNode → 单点故障(SPOF)极其严重
一旦 NameNode 挂掉:
整个 HDFS 不能读写
元数据无法访问
DataNode 保活依赖 NN,系统完全不可用
因此在 Hadoop2.x 中,HA 架构成为必然选择。
2. HDFS 中 HA 主要解决的问题

2.1 解决 NameNode 单点故障(SPOF)
通过 主备 NameNode(Active / Standby) 的方式,让一个节点故障时能立刻切换,保证 HDFS 的持续可用性。
2.2 元数据的同步一致性问题
多个 NN 如何保证元数据一致,是设计核心(QJM / NFS 等)。
2.3 为联邦(Federation)铺路
在 Hadoop2.x 中支持多个 NameNode,每个管理不同命名空间,实现元数据的水平扩展。
3. HA 的基本工作模式:Active / Standby NN
HDFS HA 启动后,会运行两个 NN:
Standby 始终保持随时可切换状态。
📌 关键:两者元数据必须保持实时一致!
4. NN 元数据组成
HDFS 元数据在磁盘上由两类文件构成:
4.1 Fsimage
文件系统的 全量快照
包含目录树、文件属性、块信息等
不频繁更新(因为写入 Fsimage 成本高)
4.2 EditLog
记录所有文件系统操作的 增量日志(类似 MySQL binlog)
频繁写入
每一次元数据变更(创建、删除、重命名)都会记录成日志
为什么必须同时使用 Fsimage + EditLog?
Fsimage 是静态快照,而 EditLog 是增量操作日志。
启动 NN 时需要:
Fsimage + EditLog = 最新完整元数据
5. HA 关键机制:Checkpoint(元数据合并)
NameNode 的 EditLog 会随着操作不断增大,为避免文件过大、重启成本高,需要定期把日志合并进 Fsimage:
→ 这个工作由 Standby NN 来执行(原 SNN 的职责被整合)
合并触发条件
由两个配置决定:
6. 元数据合并(Checkpoint)流程
下面是整个 Standby NN 合并元数据流程的完整步骤:
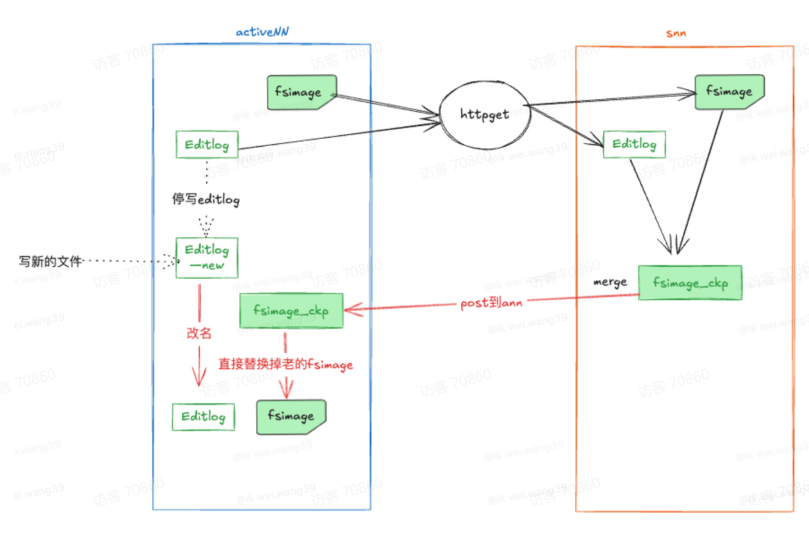
步骤 1:Standby NN 判断是否需要触发合并
依据:
时间间隔是否达到
EditLog 量是否超过阈值
如未达到 → 继续等待
步骤 2:Active NN 滚动 EditLog
Standby 发送合并请求后,Active NN:
停止往当前 EditLog 写入
创建新的文件:
edits_inprogress → edits_inprogress_new
后续的增量日志写入新文件
→ 保障旧 EditLog 是一个“稳定日志文件”,可供下载
步骤 3:Standby NN 下载元数据文件
Standby 通过 HTTP 获取:
最新的 Fsimage
完整的 EditLog 文件
下载后准备进行合并。
步骤 4:Standby NN 执行元数据合并(Merge)
过程:
加载 Fsimage(全量快照)
按顺序 replay EditLog(重放操作日志)
得到最新的元数据信息
生成新的
fsimage.ckpt文件
步骤 5:将合并结果回传给 Active NN
Standby 把生成的 fsimage.ckpt 提供给 Active NN。
Active NN 做两件事:
用新的 fsimage 替换原来的 fsimage
将
editlog_new→ 重命名为正式的 EditLog
→ 完整的“偷梁换柱”,实现元数据无缝切换
7. NN HA 的核心:元数据一致性如何保证?
元数据一致性是 HA 的重中之重,否则主备切换将导致目录树混乱。
Hadoop2 使用两种方式解决:
7.1 QJM(Quorum Journal Manager)——最常用
使用 JournalNode 集群(通常 3 或 5 台)保存 EditLog 日志。
Active NN 写 EditLog → 写入多个 JN → Standby 从 JN 拉日志
确保一致性依赖:
少数派容错(quorum)机制
只要超过半数 JN 成功写入,EditLog 就算成功。
✔ 强一致
✔ 停机可恢复
✔ 是生产环境推荐方式
7.2 NFS 方式(基本已淘汰)
NN 将 EditLog 写入共享存储(NFS Mount)。
缺点:
单一 NFS 文件系统容易成为新单点
性能差
不适用于大规模集群
8. HA 下的主备切换机制(Failover)
HDFS 使用 ZKFC(Zookeeper Failover Controller)实现主备切换:
ZKFC 功能:
健康检测(NN 是否存活)
心跳管理
选举 Active / Standby
自动 failover
主备切换触发时机:
Active NN 崩溃
Active 与 Zookeeper 失联
手动切换(运维)
保证客户端操作不受影响。
9. 总结(面试话术)
最后提供一个 可直接用于面试的总结版回答:
NN 的 HA 是 Hadoop2.x 引入的高可用机制,用于解决 Hadoop1.x 中 NameNode 的单点故障问题。通过 Active/Standby 双 NN 架构配合 ZKFC 实现自动主备切换,保证 HDFS 的高可用性。
元数据由 Fsimage 和 EditLog 构成,Standby NN 负责定期执行 Checkpoint,通过滚动 EditLog 方式从 Active 下载元数据合并成新的 fsimage,再返回给 Active 替换原有元数据,实现系统元数据的一致性与稳定性。
EditLog 同步由 QJM(JournalNode 集群)保障强一致性,是生产环境最常用 HA 架构。