

📚 数据仓库学习笔记(Data Warehouse Learning Notes)
一、数据仓库基本概念
(一)核心定义
数据仓库(Data Warehouse,DW / DWH) 是为 数据分析与决策支持 而设计的企业级数据管理系统。
它不仅仅是“存储数据的地方”,而是一个面向分析的完整系统。
核心特征:
💡 总结:数仓的“仓库”只是比喻,本质是 数据分析与决策支持系统。
(二)核心价值与应用场景
(三)与传统数据库的区别
二、数据仓库整体架构
数据仓库的核心理念是 “分层设计” —— 让数据从“原始 → 清洗 → 汇总 → 应用”逐步演变,形成可复用的数据体系。
(一)经典五层架构
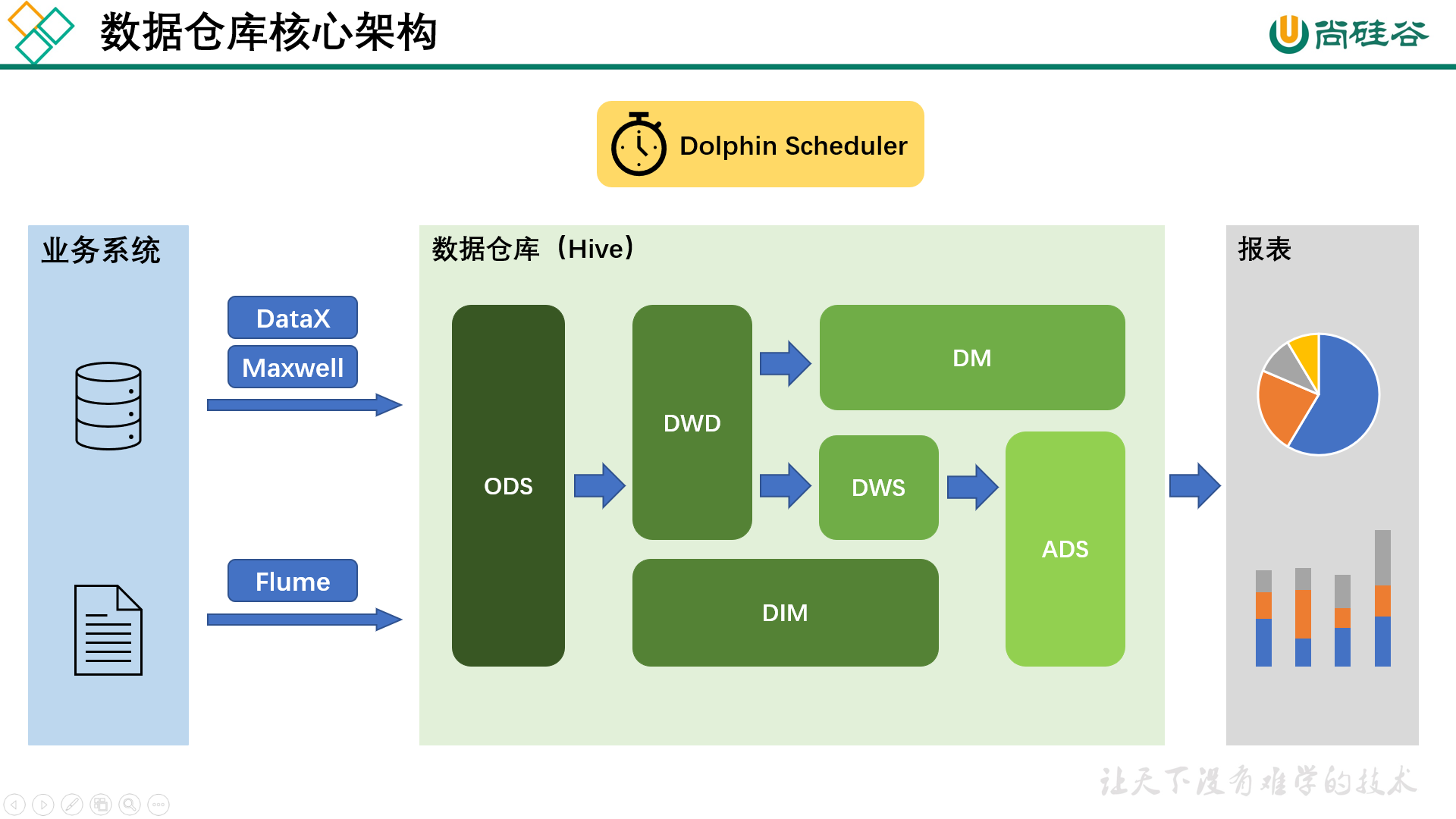
(二)关键系统组件
📥 数据采集层(入口)
作用:负责外部数据接入 ODS。
常用工具:Flink(实时)、DataX(离线)、Logstash(日志)。
示例:每日凌晨通过 DataX 同步 MySQL “订单表” 至 ODS。
⚙️ 任务调度层(引擎)
作用:管理各层任务执行顺序与依赖。
常用工具:Airflow、DolphinScheduler。
逻辑:
确保 ODS → DWD → DWS 的依赖顺序。
异常自动重试与告警。
📊 可视化层(出口)
作用:将 ADS 层结果展示为图表。
常用工具:Tableau、PowerBI、FineBI。
示例:用 Tableau 展示“月度区域销量对比图”。
(三)离线数仓 vs 实时数仓
三、数据仓库学习重点
📘 数仓学习三大核心:建表建模 → SQL 开发 → 任务调度
优先级:建模 > 调度 > SQL
(一)重点 1:建表建模 —— 数仓的“骨架”
🎯 核心目标
通过合理建模,提升数据复用性与查询性能。
🚫 反例
直接在 ODS 上做复杂 SQL,导致性能差、字段不规范、维护困难。
✅ 正例
在 DWD 清洗字段 → DWS 汇总主题 → ADS 提供分析结果,实现层层复用。
🔍 关键知识点
(二)重点 2:SQL 开发 —— 数仓的“工具”
⚙️ 核心定位
SQL 是数仓加工的主要语言,用于数据清洗、聚合、计算。
🧩 常见场景
📈 学习要点
性能优化:
使用分区查询(
WHERE dt='2025-10-20')。减少无关 JOIN。
充分利用索引。
业务逻辑转化:
将自然语言需求转化为 SQL:SELECT province, COUNT(DISTINCT user_id) AS new_users FROM user_register WHERE dt BETWEEN date_sub(current_date, 7) AND current_date GROUP BY province;学习策略:
每天练习 1-2 个业务分析题(如“用户复购率”“商品销量 TOP10”)。
(三)重点 3:任务调度 —— 数仓的“引擎”
🧠 核心作用
保证各层任务按依赖顺序定时执行,是数仓落地的关键。
🏗️ 学习重点
四、学习路径与进阶方向
🪜 学习顺序
理解概念与架构 → 建立整体认知
掌握建模设计 → 打牢数仓核心
熟练 SQL 开发 → 具备数据加工能力
学习任务调度 → 实现生产落地