

1.1 Hive 架构解析
Hive 是一个基于 Hadoop 的数据仓库工具,用于进行大规模数据的提取、转换、加载(ETL)。
它将 SQL 查询转换为 MapReduce / Tez / Spark 任务来执行。
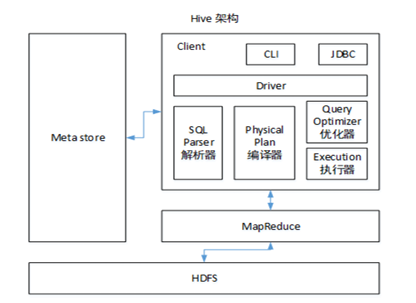
🧩 架构组成
Client(客户端):用户提交查询语句
Driver(驱动器):解析 SQL,生成执行计划
Compiler(编译器):将 HQL 编译为 MapReduce / Tez / Spark 任务
MetaStore(元数据存储):保存表结构、分区信息等元数据,通常存放在 MySQL 中
Execution Engine(执行引擎):负责任务调度与执行
HDFS(存储层):实际存放数据文件
1.2 Hive 与传统数据库的比较
💡 结论:Hive 更像是面向批量数据分析的“SQL 封装层”,不适合实时查询。
1.3 内部表与外部表
Hive 表分为两类:内部表(Managed Table) 和 外部表(External Table)
✅ 建议:生产环境优先使用外部表,防止误操作导致数据丢失。
1.4 四种 By 的区别
⚙️ 生产建议:常用 Sort By + Distribute By,避免使用 Order By。
1.5 常用系统函数 🧮
1.6 自定义函数(UDF / UDTF)
✳️ UDF(单行 → 单行)
用于对单个输入列进行处理。
继承 UDF 类,重写 evaluate() 方法。
✳️ UDTF(单行 → 多行)
用于将一行展开为多行。
继承 GenericUDTF 类,重写以下方法:
initialize():定义输出列结构process():处理逻辑close():清理资源
💡 项目经验:
使用自定义 UDF 解析公共字段
使用 UDTF 解析嵌套 JSON 事件字段
可在函数中打印日志方便调试
1.7 窗口函数讲解 🪟
常见函数
RANK():名次相同会跳级DENSE_RANK():名次相同不跳级ROW_NUMBER():严格排序,无并列
OVER() 子句参数说明
CURRENT ROW:当前行
n PRECEDING:往前 n 行
n FOLLOWING:往后 n 行
UNBOUNDED PRECEDING:从分区头开始
UNBOUNDED FOLLOWING:到分区末尾
LAG(col,n):往前第 n 行
LEAD(col,n):往后第 n 行
NTILE(n):将数据分成 n 个桶返回编号
💡 应用案例:计算用户近 7 日留存率、TopN、环比、同比等。
1.8 Hive 优化策略 🚀
1️⃣ MapJoin(小表放内存)
避免大表与大表 JOIN,可用以下参数:
set hive.auto.convert.join=true;
2️⃣ 行列过滤
只选取需要的列:
SELECT col1, col2尽量使用分区过滤字段
3️⃣ 分区与列式存储
分区字段:日期 / 地区 / 类型等
推荐存储格式:ORC / Parquet
4️⃣ 控制 Map / Reduce 数量
通过设置数据块大小来控制 map 数量:
set mapred.max.split.size=256000000;
set mapred.min.split.size=134217728;
过多 Reduce 会产生小文件问题。
5️⃣ 小文件优化
使用
CombineHiveInputFormat启用文件自动合并:
set hive.merge.mapfiles=true;
set hive.merge.mapredfiles=true;
set hive.merge.size.per.task=268435456;
6️⃣ 压缩与执行引擎选择
开启中间结果压缩可减少 I/O
选择 Tez 或 Spark 引擎比 MR 更高效
1.9 数据倾斜问题 ⚖️
📉 常见原因
不同类型字段 JOIN(如 int 与 string)
空值过多导致聚合集中
数据分布极度不均衡
🛠 解决方案
类型转换统一
on a.user_id = cast(b.user_id as string)空值打散
concat('null_', rand())使用 MapJoin 让小表提前加载
负载均衡参数设置
set hive.groupby.skewindata=true;当启用此参数时,会自动将 GroupBy 操作分为两阶段 MapReduce 执行,以实现负载均衡。
1.10 Hive 字段分隔符
Hive 默认字段分隔符为 ASCII 控制符 \001(^A),创建表时使用:
FIELDS TERMINATED BY '\001'
若采用 \t 或其他字符作为分隔符,需确保前端日志中无该符号。
若存在冲突,应在上游 ETL 阶段进行转义或替换。
1.11 Tez 引擎优点
Tez 可将多个有依赖的作业合并为一个任务,减少落盘操作,提高性能。
1.12 MySQL 元数据备份
Hive 元数据通常存放在 MySQL 中,务必定期备份。
建议每日零点后备份至其他服务器两份
可用 Keepalived / MyCat 保障高可用
若出现
Incorrect string value错误:原因:utf8 仅支持 3 字节字符
解决:改为
utf8mb4编码
1.13 Union 与 Union All 区别
💡 实际应用中,若不需要去重,优先使用 UNION ALL 提高效率。
✨ 总结
Hive 是构建数仓的重要组成部分,擅长处理大规模离线数据。
掌握其执行机制、优化手段、UDF/UDTF 开发与常见问题处理,是成为高级大数据工程师的重要一步。