

1️⃣ Spark 架构回顾:系统组件与职责拆解
在理解任务提交流程前,必须先弄清楚 Spark 在集群中的角色和通信模型。
Spark 的整体架构如下:
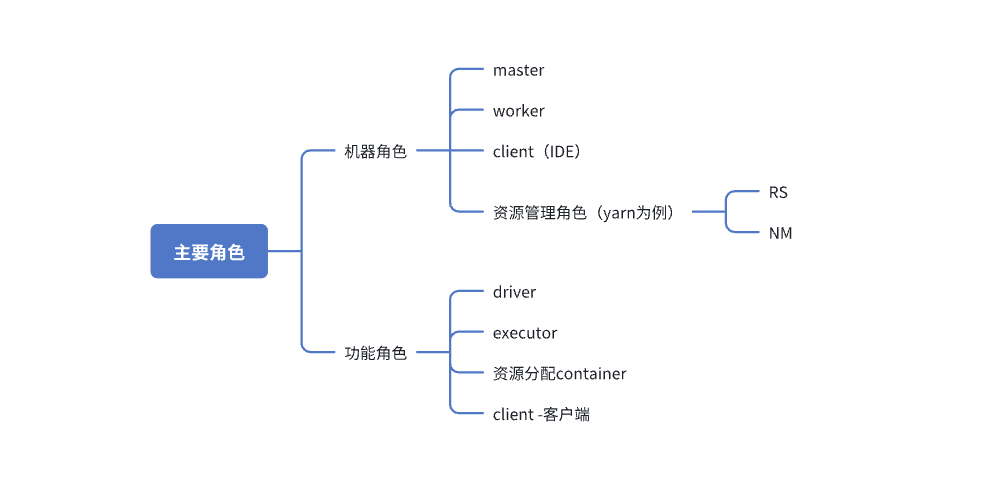
角色(实际存在的物理 / 虚拟节点)
你提交的 Spark 应用最终会在这些节点组合中运行。
1.2 ⚙ Spark 运行组件(进程级角色)
Driver 是 Spark 应用的大脑,Executor 是手脚。
1.3 🔌 资源角色(由 Yarn/Master 提供)
2️⃣ Spark 作业运行模式详解(Local / Standalone / YARN / K8s)
不同运行模式决定 ——
Driver 启动位置、资源申请方式、作业可靠性。
这是 Spark 最容易混淆的部分,也是面试核心考点。
2.1 🏠 Local 模式(本地模式)
特点:
单机运行(不依赖集群)
用于测试和开发
“线程模拟集群模式”
常见:
local
local[N]
local[*]
local[K,F]
local[*] → 使用机器全部 CPU
local[K,F] → K 个执行线程、F 次重试
2.2 🏢 Standalone 模式(Spark 自带集群)
特点:
Spark 自己管理资源
Master 调度 Worker 的资源
适用于教学、小公司
核心角色:
Master 负责调度
Worker 提供资源
2.3 🎩 YARN 模式(企业生产最常用)
特点:
资源完全由 YARN 调度,Hadoop 生态下标准方式
高可用、容错强、调度能力强
两种方式:
yarn-client
yarn-cluster(生产环境推荐)
2.4 ☁ Kubernetes 模式(云原生)
不展开,主要是 Pod 管理 Executor 与 Driver。
3️⃣ Client 模式 vs Cluster 模式(Driver 位置决定一切)
Driver 运行在哪里?是最终决定提交模式的根本区别。
3.1 Client 模式(Driver 在客户端机器)
流程:
Client 创建 Driver
Driver 与集群通信
Executor 在集群运行
特点:
客户端压力大
客户端不能掉线(Driver 挂了整个作业失败)
适合交互式分析(spark-shell)
3.2 Cluster 模式(Driver 在集群节点)
Driver 不再运行在客户端,而是:
Standalone → 由 Master 选择某台 Worker 启动 Driver
YARN → 由 ApplicationMaster 的 Container 启动 Driver
优势:
客户端完全无压力
Driver 可自动重启
更适合生产离线任务
⚠ 面试高频问题:
yarn-cluster 中 AM 就是 Driver。
4️⃣ Standalone-Cluster 模式任务提交流程
下面是最完整、最清晰的 Standalone 提交流程讲解。
完整流程图:
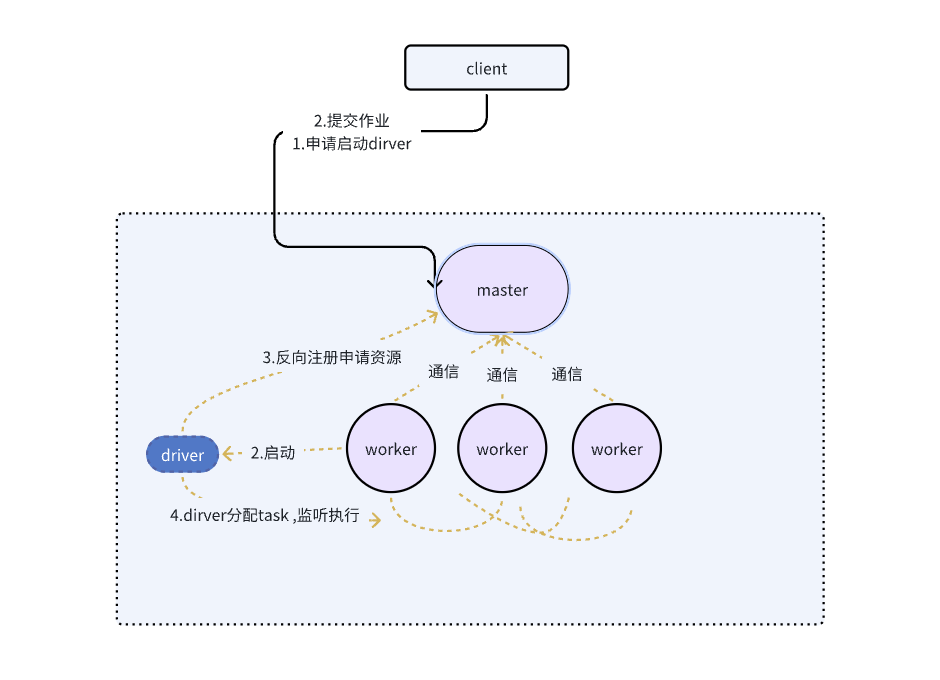
4.1 📌 详细流程步骤
(1)Client 执行 spark-submit
提交命令后:
Client 构建提交请求,携带 jar、依赖、配置等信息
与 Master 建立连接
(2)Master 选择一个 Worker 启动 Driver
Master 会:
寻找可用 Worker
分配一个 Worker 启动 Driver 进程
下发启动参数给 Worker
此时客户端不再参与后续执行。
(3)Driver 启动后向 Master 注册
Driver 的职责:
加载用户代码
初始化 SparkContext
构建算子链(RDD → Lineage)
生成 DAG / Stage / Task
Driver 非常重要,它是整个逻辑的大脑。
(4)Driver 向 Master 申请 Executor 资源
Driver 上构建完 DAG 后,开始:
计算需要多少 Executor
向 Master 发起资源申请
(5)Master 分配 Worker 节点运行 Executor
Master 会在多个 Worker 上启动 Executor。
每个 Executor 是一个独立 JVM。
(6)Executor 启动后向 Driver 注册
Executor 告诉 Driver:
我已经就绪
我能执行 Task
Driver 记录这些 Executor 的资源信息。
(7)Driver 向 Executor 下发 Task
任务调度开始:
Stage 内所有 Task 由 Driver 下发
Executor 拉取数据执行 Task
(8)Task 运行完成 → Driver 收集结果 → 作业结束
Driver 收到任务完成状态后:
标记 Stage 结束
最终整个 Job 完成
清理资源
5️⃣ YARN-Cluster 模式任务提交流程(最标准生产流程)
流程图:
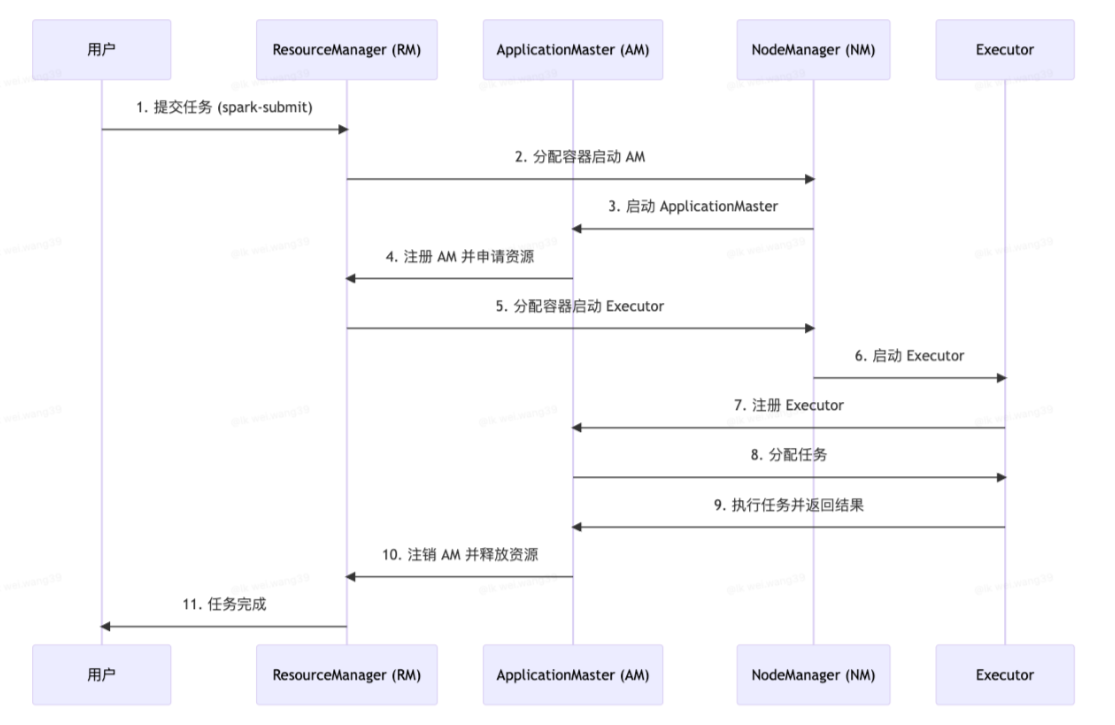
这是最常用、最推荐的 Spark 生产模式。
5.1 🔍 详细 9 步流程
(1)Client 执行 spark-submit(–deploy-mode cluster)
提交后:
将应用 Jar
配置文件
运行参数
发送给 RM。
(2)ResourceManager 分配第一个 Container
这个 Container 用来启动 ApplicationMaster(AM)。
(3)NodeManager 启动 ApplicationMaster(AM)
AM 在 Spark 中的角色:
在 yarn-cluster 中 AM = Driver
在 yarn-client 中 AM 只负责资源申请
这是最重要的区别!
(4)AM 注册到 RM 并申请资源(用于 Executor)
AM 启动后需要:
告诉 RM 我要多少 Executor
告诉 RM 每个 Executor 的 CPU/Memory
(5)RM 分配多个 Container 用于启动 Executor
根据需求:
RM 会选择多个 NodeManager
分配对应数量的 Container
(6)NodeManager 启动 Executor 进程
每个 Executor 是一个 JVM。
(7)Executor 向 AM 注册
注册后表示“我已经准备好执行 Task”。
(8)AM 开始下发任务(Task Scheduling)
Executor 获取 Task 后执行:
计算
Shuffle 写
Shuffle 读
结果回传 AM
(9)任务完成 → AM 注销 → 释放资源
最后:
AM 通知 RM:任务成功
RM 回收 Container
整个应用结束
6️⃣ YARN-client 模式(对比 yarn-cluster)
Driver 在客户端运行,流程不同:
Client 启动 Driver
Driver 向 YARN 申请资源
YARN 启动 AM(此时 AM 不包含 Driver)
AM 只负责 Executor 的资源申请
Driver 调度所有任务
缺点:
客户端压力大
客户端不能掉线
7️⃣ Master URL 参数详解(spark-submit 小知识)
Master URL 决定运行模式。
8️⃣ “Driver 是整个系统核心”的深度说明(非常关键)
Driver 负责:
加载用户代码
构造 RDD 血缘(Lineage)
划分 Job / Stage / Task
根据宽窄依赖拆分 DAG
申请资源
调度 Task
接收 Executor 执行结果
失败重试
完成收尾工作
一句话:
Driver 掌控整个应用的生命周期。
9️⃣ 总结(面试版)
Spark 运行模式本质取决于 Driver 位置
Standalone 和 YARN 的区别是:谁管理资源
Yarn-cluster 下 AM = Driver
Standalone-cluster 下 Driver 运行在 Worker
Client 模式不适合集群生产
Cluster 模式更稳定、更可恢复
Spark 作业执行核心流程:
提交 → Driver 启动 → DAG 构建 → 资源申请 → Executor 启动 → Task 执行 → 完成