

🚀 1. MapReduce 概述
MapReduce 是 Hadoop 生态中用于 离线批处理 的核心计算框架。
它可以在 成百上千台机器 上并行处理 TB~PB 级数据,具备:
分布式计算能力
自动容错
自动任务调度
自动数据分片
高扩展性
尽管 Spark 在速度和开发效率上已大幅超越 MapReduce,但很多企业仍有大量 MR 作业在运行,MR 的设计思想也深刻影响 Spark、Flink 等框架。
🧠 2. MapReduce 的设计思想
MapReduce 的理论基础是:
Divide and Conquer(分治思想)
把复杂的大规模计算任务拆解成多个可并行的小任务:
Map:将输入转化为一批 key → value(映射)
Shuffle:按 key 聚合 & 分发数据
Reduce:对相同 key 的 value 集合进行聚合(规约)
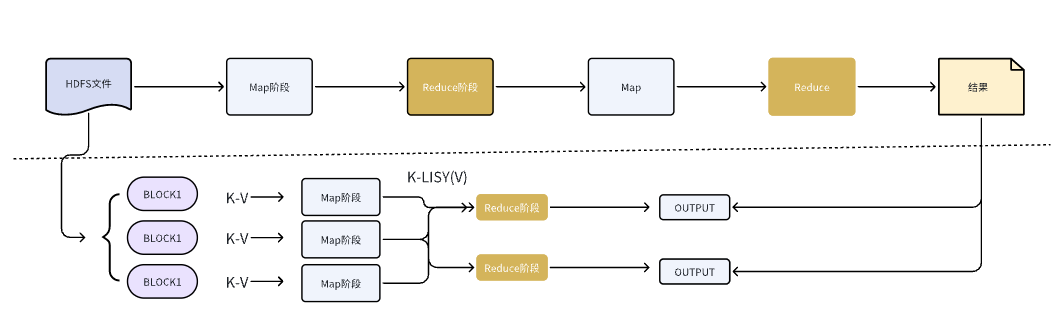
整体流程:
Map → Shuffle → Reduce → Output
甚至可以多轮串联:
MR → MR → MR → MR ...
Spark RDD 的设计就是对 MR 思想的升级:
去磁盘
pipeline 化处理
DAG 调度
🌟 3. MapReduce 的主要特点(优缺点全面解析)
🌈 3.1 优点(曾经的王者)
适合海量数据(TB~PB)运算
编程模型简单(Map、Reduce 两个函数)
自动容错(节点挂了自动重跑)
与 HDFS 深度集成(数据本地化执行)
可横向扩展(scale-out)
自动处理任务调度、数据切片、异常重试等繁琐操作
⚠️ 3.2 缺点(Spark 取代的根本原因)
大量磁盘 I/O
Shuffle 开销巨大
实时性差 → 延迟高
链式 MR 任务太多导致效率低
不适合迭代计算(机器学习、图计算)
📘 4. WordCount 示例(贯穿 MR 机制的最佳案例)
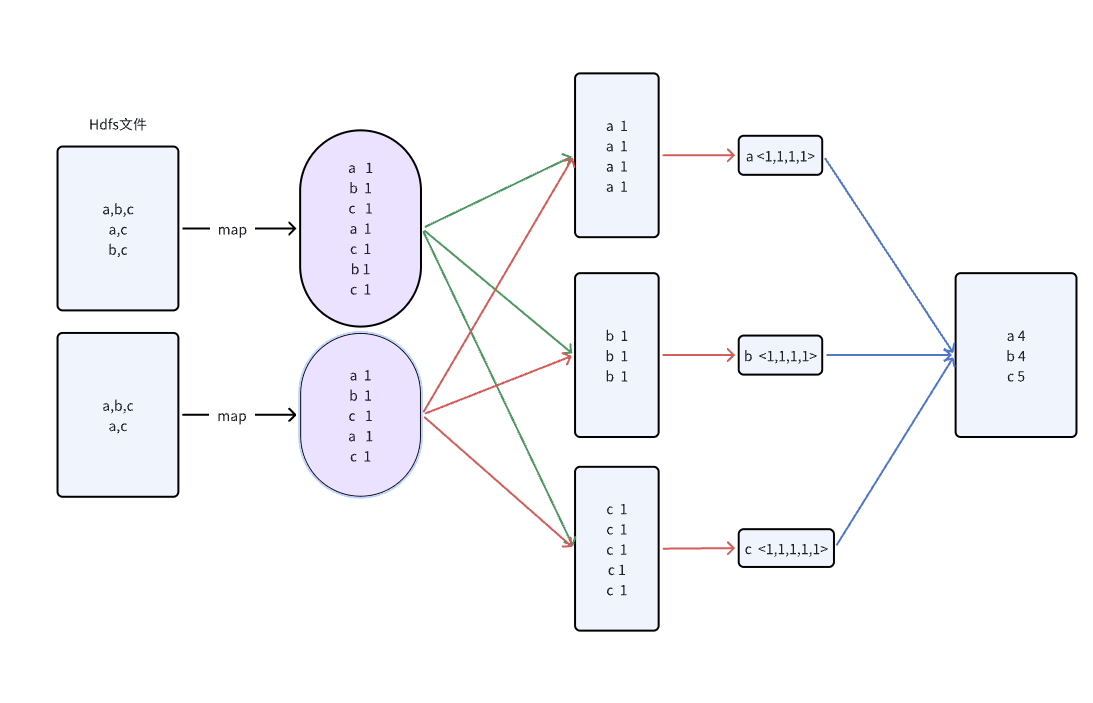
输入(HDFS 文件):
a b c
a c b
a
🗂️ 4.1 Map 阶段输出:
WordCount 的 Map 输出:
(a,1)
(b,1)
(c,1)
(a,1)
...
🔄 4.2 Shuffle 后:
a → <1,1,1,1>
b → <1,1>
c → <1,1,1,1,1>
🧮 4.3 Reduce 阶段聚合:
a → 4
b → 2
c → 5
WordCount 虽简单,却完整覆盖 MR 的核心流程,是最典型的入门案例。
📦 5. MapReduce 编程模型(Map / Reduce / Driver)
🧩 5.1 Map 阶段:解析输入 → 输出 KV
Map 的典型职责:
读取切片内数据
按格式解析(行、JSON、CSV)
输出
<key, value>写入环形缓冲区(shuffle 缓冲区)
Map 输出不能太大,否则会触发频繁的 spill(性能差)。
🔧 5.2 Reduce 阶段:对相同 key 聚合
Reduce 输入格式:
key → [value1, value2, value3 ...]
Reduce 的典型任务:
求和(Sum)
统计(Count)
最大最小值(Max/Min)
分组聚合(Group Aggregation)
Join(Reduce Join)
去重(Distinct)
最终输出写入 HDFS。
🧰 5.3 序列化机制(Writable)
MapReduce 的数据格式必须支持跨节点传输,因此采用:
Writable(Hadoop 自定义序列化格式)
更轻量,效率比 Java Serializable 高得多
常用类型:
Text(字符串)
IntWritable
LongWritable
BooleanWritable
ArrayWritable
使用 Writable 的原因:
数据量大,需要高压缩率、高效率
Map → Shuffle → Reduce 传输高频,需要轻量结构
📍 6. 数据分片(InputSplit)机制
InputSplit 决定每个 MapTask 处理的数据范围。
📌 核心原则:
默认与 HDFS Block(128MB) 对齐
每个 split 对应一个 MapTask
split 由 客户端计算(非 DataNode)
可以合并小文件(CombineInputFormat)
📐 分片核心逻辑:
伪代码:
splitSize = max(minSize, min(goalSize, blockSize))
这就是为什么大量小文件会导致:
MapTask 爆炸
Job 启动时间变长
整体效率低
🔥 7. Shuffle 机制(MR 的灵魂 + 性能瓶颈)
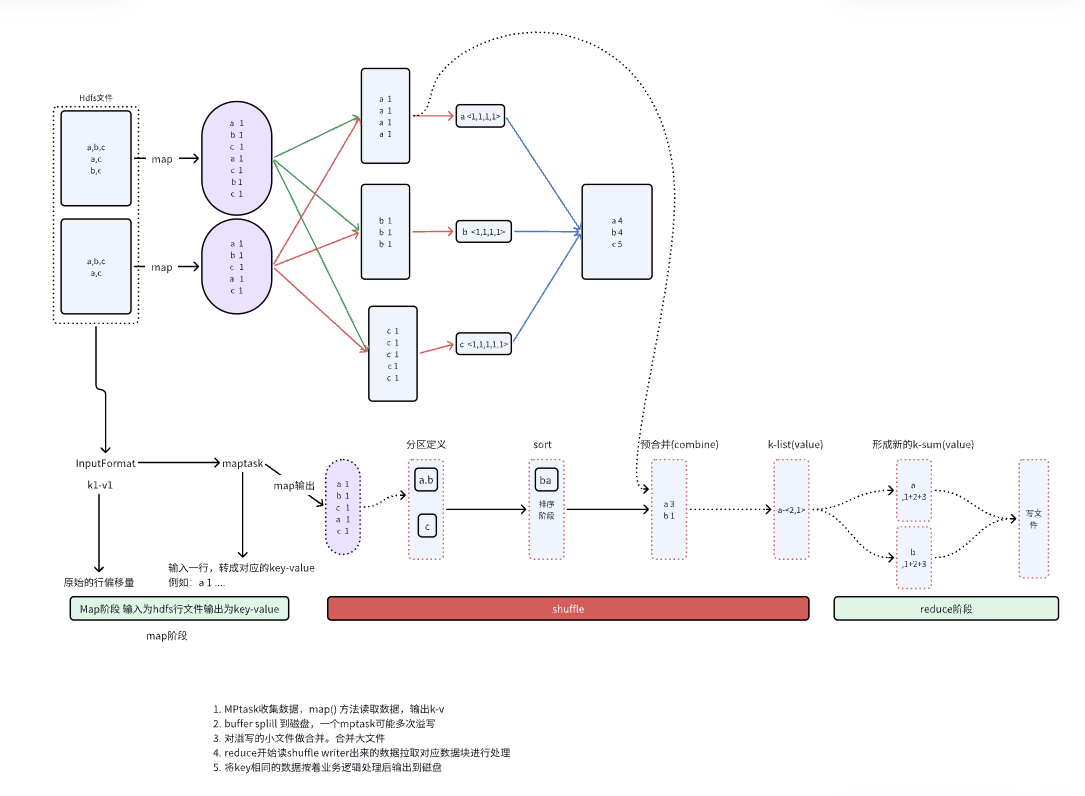
Shuffle 是 MR 最重要、最复杂的一环。
它完成:
分区(Partition)
排序(Sort)
归并(Merge)
数据拉取(Fetch)
Shuffle 决定:
Reduce 能否按 key 正确收到数据
作业整体执行速度
是否出现数据倾斜
Shuffle 是整个 MR 性能的 生死线。
🌀 8.1 Map 端 Shuffle 详细流程(重点)
Map 输出先进入:
✔ 环形缓冲区(Circular Buffer)
当缓冲区达到 80% 阈值后触发:
🔥 SPILL(溢写磁盘)
spill 步骤:
按 key 排序
按分区分组
写入磁盘 → 生成一个 spill 文件
一个 MapTask 往往会 spill 多次。
🔄 Map 端合并(Merge)
多个 spill 文件会被合并成一个最终文件:
每个 partition 一个文件块
分区内有序(后续 Reduce 可合并)
🌀 8.2 Reduce 端 Shuffle 详细流程(重点中的重点)
ReduceTask 会从所有 MapTask 拉取自己分区对应的数据:
流程:
根据分区号,通过 HTTP 远程拉取 Map 输出
将多个 Map 输出文件进行 归并排序(merge sort)
得到按 key 排序好的大文件
传入 Reduce 程序进行聚合
这一过程非常容易导致:
网络瓶颈
数据倾斜
reduce 卡住很长时间
🧵 9. Shuffle 总流程图
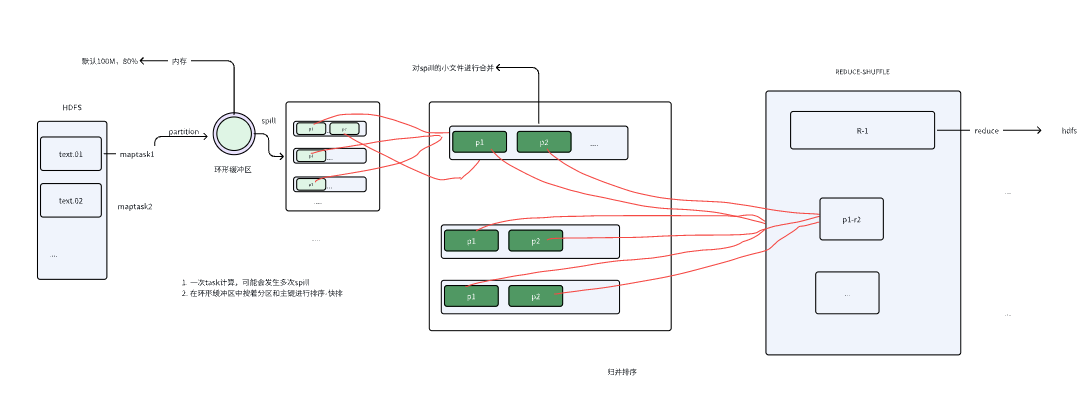
✨ 两次落盘:
Map spill
Map merge
✨ 多次排序:
spill 时快排
merge 时多路归并
reduce 端再次归并
Shuffle 是 MR 最慢的环节。
🗜️ 10. MapReduce 数据压缩(性能优化关键点)
为什么压缩?
降低 Map → Reduce 传输量(网络压力骤降)
减少磁盘写入量(减少 spill 大小)
提升 Shuffle 整体速度
大原则:
IO 密集 → 压缩比大一些
计算密集 → 压缩比小一些
🧾 11. MapReduce 总结
一句话总结:
MapReduce 是一种基于分治思想的分布式计算框架,通过 Map 生成 key-value、Shuffle 分区排序、Reduce 聚合,最终完成海量数据批处理,是 Hadoop 的核心执行模型。
面试必问知识点:
Map / Reduce 的完整执行流程
InputSplit vs Block
Shuffle 的详细机制
Spill 什么时候发生
为什么 Shuffle 是 MR 的性能瓶颈
Combiner 如何减少网络传输
分区器如何决定 Reduce 个数