

在大数据计算中,Join 是最常见、最核心、也是最昂贵的操作之一。
Spark 为适配不同数据规模和计算需求,提供了 5 大 Join 策略:
Broadcast Hash Join
Shuffle Hash Join
Sort Merge Join
Cartesian Join
Broadcast Nested Loop Join
Spark 在执行计划优化阶段(Catalyst Optimizer),会基于数据量、Join 条件、排序情况自动选择最优策略。
📌 1. Broadcast Hash Join(广播哈希 Join)
🎯 适用场景
大表 JOIN 小表(典型使用场景)
小表需能放入 Executor 内存
Join 条件必须是 等值连接(=)
📦 触发方式
Spark 会自动广播 小于 10MB 的表
控制参数:
spark.sql.autoBroadcastJoinThreshold(默认 10M)
可使用 hint 强制广播:
SELECT /*+ BROADCAST(smallTable) */ *
FROM bigTable JOIN smallTable ON ...
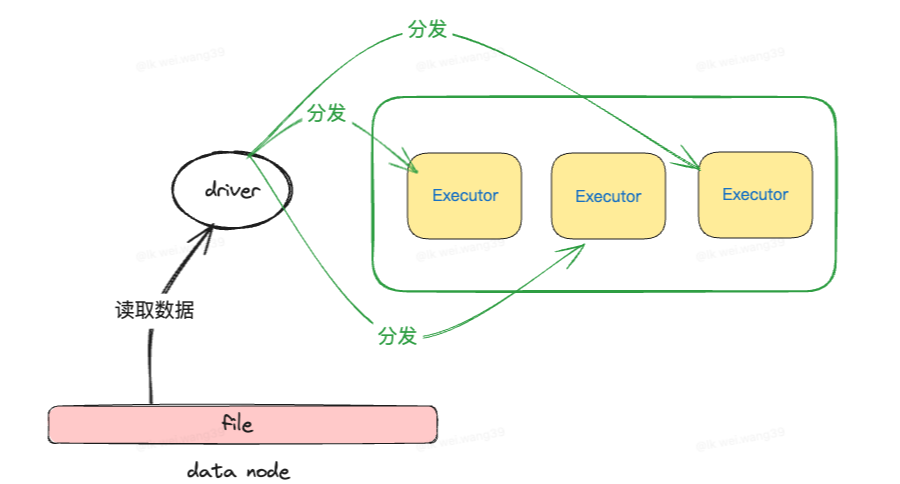
⚙️ 执行原理
Driver 读取小表并广播到所有执行节点。
每个 Executor 将广播表构建成 HashMap(key→values)。
大表数据按分区遍历,在内存进行高效的哈希匹配。
⭐ 优点
无 shuffle → 性能极高
内存 join,速度极快
⚠️ 缺点
广播表过大可能 OOM
只能用于等值 join
📌 2. Shuffle Hash Join(分布式哈希 Join)
当两表都不够小无法广播,但希望使用 Hash Join 时,会选择 Shuffle Hash Join。
🎯 适用场景
两边表都较大,但其中一边仍能在 Executor 内存构建 HashMap
Join 条件是 等值条件
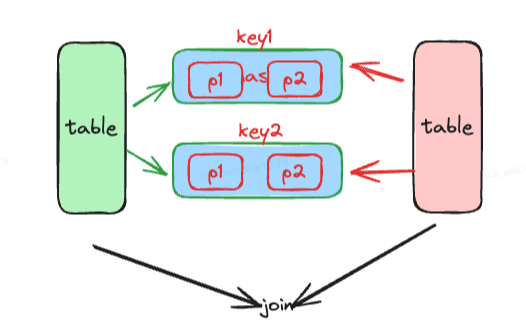
⚙️ 执行原理
Shuffle:两张表按 Join key 重新分区,使相同 key 的数据进入同一分区。
在每个分区:
选择较小的一侧构建 哈希表(HashMap)
另一侧逐行扫描并进行哈希匹配
🔍 Spark 判断是否使用 Shuffle Hash Join 条件示例:
A.sizeInBytes < spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions
A.sizeInBytes * 3 <= B.sizeInBytes
⭐ 优点
在可构建内存 hash 的情况下,比 Sort Merge Join 更快
适用于数据中等规模的不均匀场景
⚠️ 缺点
大量 shuffle
一侧数据仍需能在内存放下,否则会 OOM
📌 3. Sort Merge Join(排序合并 Join)【默认策略】
这是 Spark 默认的 Join 策略
(参数:spark.sql.join.preferSortMergeJoin = true)
🎯 适用场景
大表 JOIN 大表
数据规模极大
Join key 必须为 等值连接
即使数据量巨大也不会 OOM(可溢写磁盘)
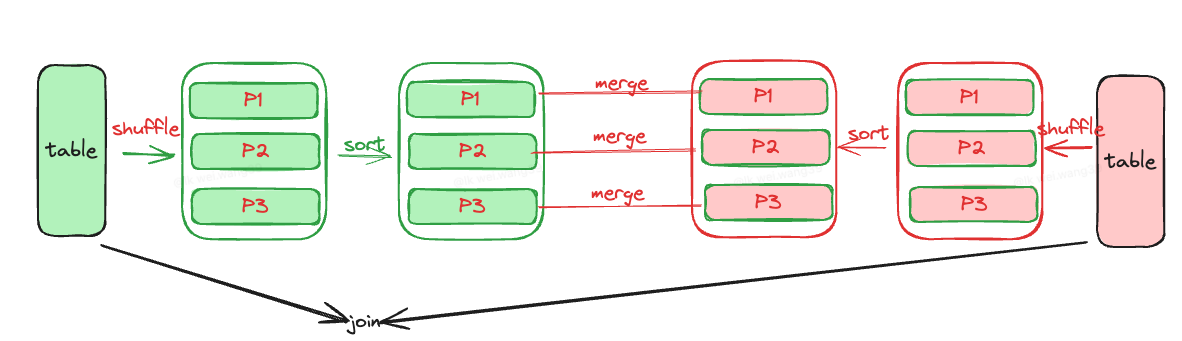
⚙️ 执行原理
Shuffle:按 Join key 分区,使同 key 数据进入同一分区。
Sort:对每个分区按 key 排序。
Merge:左右已排好序 → 使用 双指针扫描 合并输出。
⭐ 优点
可处理超大规模数据集(可落盘)
稳定可靠,是大多数场景的最终 fallback
⚠️ 缺点
需要排序 → 开销较大
总是伴随 shuffle → 延迟较高
📌 4. Cartesian Join(笛卡尔积 Join)
当 没有 Join 条件 或条件不合法时,Spark 会执行完整的笛卡尔积。
🎯 适用场景
CROSS JOIN明确声明非等值 Join 下无法采用其他策略时可能 fallback
⚙️ 执行原理
对 A、B 两表做全组合:
结果数量 = A 行数 × B 行数
⚠️ 风险
⚠️ 数据爆炸风险极高
因为通常:
10 万 × 10 万 = 100 亿条数据
默认禁用,需要开启:
spark.sql.crossJoin.enabled = true
⭐ 场景
小数据集进行业务逻辑笛卡尔组合
机器学习特征组合场景(有限使用)
📌 5. Broadcast Nested Loop Join(广播嵌套循环 Join)
在无其他策略可选时的最终退路。
🎯 适用场景
Join 条件不是等值(例如:> < >= <=)
无可排序 key 的情况
其中一张表较小,可广播
一般为 非等值 join 的备选方案:
A.col > B.col
A.time BETWEEN B.start AND B.end
⚙️ 执行原理
Spark 广播其中一个较小的表。
在每个 Executor 对大表进行 嵌套遍历:
对大表每一行
遍历小表所有行
比较是否满足 join 条件
⭐ 优点
支持非等值 join
不要求 key 排序
⚠️ 缺点
❌ 复杂度高:O(N × M)
❌ 性能最差的 join 策略
❌ 大表绝对不能放这类 join(会爆炸)
⚖️ Spark Join 策略选择优先级(等值 Join)
Spark Catalyst 优化器的选择顺序如下:
Broadcast Hash Join(小表存在 → 优先最高)
Sort Merge Join(默认策略)
Shuffle Hash Join(适合中等规模数据)
Cartesian Join(无 join key 时)
Broadcast Nested Loop Join(最差策略,仅在无路可选时使用)
🔑 Join 策略影响因素(核心)
1. 是否显式 hint
/*+ BROADCAST(t) *//*+ SHUFFLE_HASH(t) */hint 优先级最高
2. Join 条件类型
3. 数据集大小
小表 → Broadcast Hash Join
大表 → Sort Merge Join
超级大表 → Sort Merge Join(可落盘)
4. 是否已排序
已排序 → Sort Merge Join 性能更好
📝 总结(高频面试题)
✔ 为什么 Broadcast Join 快?
因为避免了 shuffle,小表直接广播到每个 Executor 内存中。
✔ Sort Merge Join 为什么是默认策略?
能处理最大规模的数据
稳定、安全,不会 OOM
适用于大多数实际生产 Join 场景