

本文从整体视角出发,讲解项目的全链路数据处理体系,包括 项目整体架构、数据采集流程 和 数仓分层设计 三大核心部分。
目标是实现从数据产生、采集、存储到价值输出的完整数据闭环。
🧩 一、项目整体架构(Data Architecture Overview)
整个系统以 “数据驱动业务决策” 为核心目标,采用分层式数据架构,将数据的生命周期划分为五个阶段:
数据产生 → 采集与存储 → 数据仓库 → 数据服务 → 可视化呈现
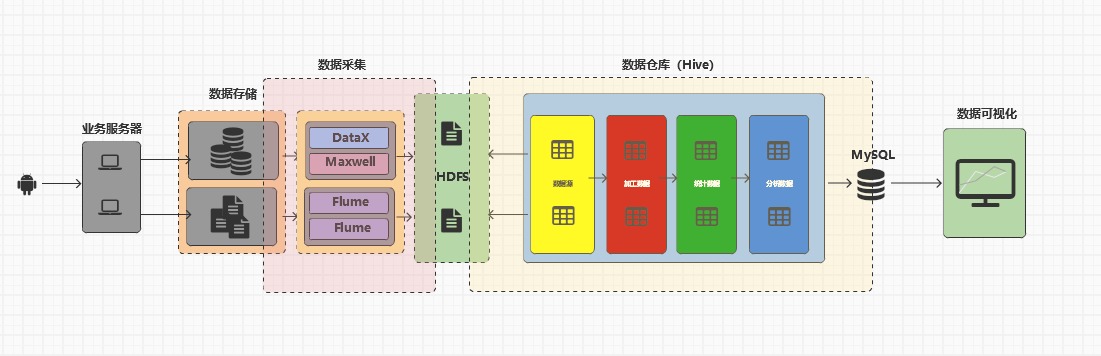
1️⃣ 数据产生层
📱 来源:主要由安卓端与业务服务器交互产生的业务数据。
💾 类型:包括用户行为日志、交易流水、系统运行日志等。
这些数据构成整个数据体系的“原材料”,是后续所有分析的基础。
2️⃣ 数据存储与采集层
存储模块:
🗄️ 数据库:存放结构化业务数据(如 MySQL)。
📂 文件存储:存放非结构化或半结构化数据(如日志文件)。
采集模块:
DataX:负责数据库全量同步(离线批量)。
Maxwell:监听 MySQL Binlog 实现实时增量同步。
Flume(双实例):采集日志数据,实现流式采集。
所有采集数据最终 统一汇聚到 HDFS,构建企业级数据湖。
3️⃣ 数据仓库层(Hive 为核心)
构建在 HDFS 之上,采用 Hive 实现数据的结构化与逻辑分层。
实现 贴源、加工、统计、分析 多层次的数据治理体系。
为上层应用提供标准化、高质量的数据支撑。
4️⃣ 数据服务与可视化层
将 Hive 中的数据同步至 MySQL,作为中间层数据库。
通过 可视化系统(如 Superset、FineBI 或 ECharts) 呈现业务指标与报表。
实现从底层数据到业务价值的“闭环转化”。
🔄 二、数据采集流程(Data Ingestion Pipeline)
数据采集是整条链路的“入口”,负责将多源数据高效、安全地汇入 HDFS。
系统支持两种主要采集模式:全量数据采集 与 增量 / 日志采集。
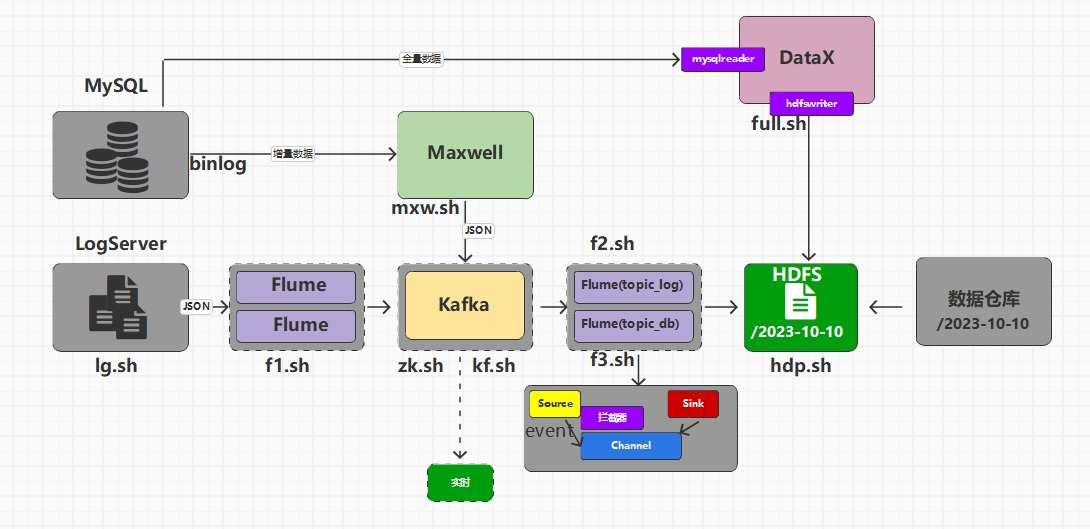
💾 1️⃣ 全量数据采集流程(MySQL → HDFS)
💡 该模式适用于周期性全量备份或基础数据初始化。
输出路径示例:/2023-10-10/
⚡ 2️⃣ 增量与日志数据采集流程
(1)MySQL 增量数据采集
✅ 实现数据库的实时变更同步,保证数据时效性。
(2)日志数据采集(LogServer → Kafka → HDFS)
💬 日志链路设计注重高并发与高可靠性,确保日志不丢失。
🧠 3️⃣ 实时支撑组件与调度体系
🔁 所有流程通过脚本自动化执行,支持定时调度与失败重试机制。
🏗️ 三、数据仓库分层设计(Hive Data Warehouse Layers)
数据仓库(Data Warehouse,简称 DW)是整个大数据架构的“核心中枢”,
承担着数据治理、加工、整合与服务的任务。
Hive 数据仓库采用 四层逻辑分层设计,从贴源到分析逐步演进:
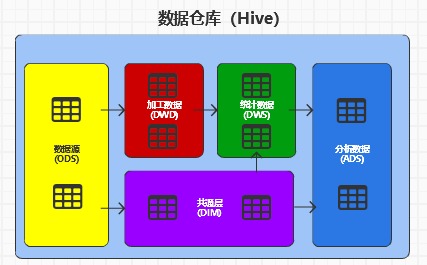
🟡 1️⃣ 贴源层(ODS,Operational Data Store)
定义:存储与业务系统对应的原始数据,保持数据原貌。
特点:不做任何清洗,仅做轻度格式化(如字段标准化)。
作用:数据追溯、问题排查的基础层。
示例路径:
/warehouse/ods/order_info/dt=2025-10-10/
🔴 2️⃣ 加工层(DW / DWD,Data Warehouse Detail)
定义:对 ODS 数据进行清洗、去重、转换、整合。
目标:形成标准化的主题数据(如用户主题、订单主题)。
处理逻辑:
统一数据格式(时间戳、地区编码等);
异常数据剔除;
主键冲突处理。
示例:
CREATE TABLE dwd_order_info AS
SELECT order_id, user_id, amount, status, create_time
FROM ods_order_info
WHERE status IS NOT NULL;
🟢 3️⃣ 统计层(DM,Data Mart)
定义:基于加工层构建指标与汇总表。
作用:为报表系统与业务分析提供统计结果。
典型内容:
日活跃用户数(DAU)
GMV(交易总额)
转化率等指标
示例路径:
/warehouse/dm/user_behavior/dt=2025-10-10/
🔵 4️⃣ 分析层(ADS,Application Data Service)
定义:面向应用的数据层,为可视化、模型训练等提供定制化数据集。
特征:高聚合度、高价值,响应速度快。
应用场景:
BI 报表(如销售漏斗、渠道转化分析)
智能推荐系统特征输入
机器学习样本生成