

1.1 Flume 架构组成
Flume 是一个分布式、高可靠的日志收集系统,主要由以下三个核心组件组成:
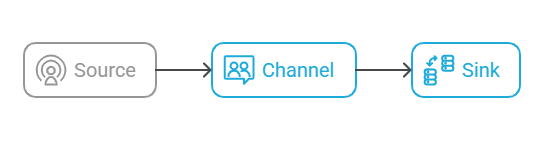
Source:负责接收数据(如监听文件、端口、Kafka 等)
Channel:暂存数据,相当于一个缓冲区(支持事务)
Sink:将数据输出到下游系统(如 HDFS、Kafka、HBase 等)
Flume 通过事务机制保证 数据不丢、不重、不乱序。
1.2 Flume 事务机制(Transaction)
Flume 使用两类事务机制确保数据传输的可靠性:
🔸 事务特性:
Flume 采用类似数据库的事务机制(begin → put/take → commit/rollback)
确保 “至少一次” 传输语义(at-least-once)
1.3 Source 模块详解 —— Taildir Source
1.3.1 🧩 Taildir Source 概述
Taildir Source 是 Flume 中最常用的文件监控 Source,功能类似 Linux 的 tail -F,支持多文件、断点续传。
1.3.2 主要特性
1.3.3 版本来源
Taildir Source由 Apache Flume 1.7 正式引入CDH 1.6 版本为早期实现(无断点续传)
1.3.4 无断点续传时代的做法
自定义开发 TailSource
手动记录 offset
或使用
Spooldir Source替代(自动归档)
1.3.5 异常与容错机制
1.3.6 重复数据处理方案
1.3.7 自定义增强(递归读取)
Taildir 默认不支持递归遍历子目录,可通过自定义 Source:
递归扫描目录
动态加载新文件
1.4 Channel 模块详解
Flume 的 Channel 相当于数据缓冲区,用于存放 Source 与 Sink 之间的数据。
1.4.1 Channel 类型比较
1.4.2 File Channel
特点:数据写入磁盘,支持事务恢复
优势:极高的可靠性
缺点:I/O 开销大,速度较慢
性能优化:可配置多个 dataDirs 路径,分布在多块硬盘上,提升吞吐量
dataDirs=/disk1/flume_data,/disk2/flume_data
1.4.3 Memory Channel
特点:数据保存在内存中
优势:速度快,延迟低
缺点:可靠性差,进程中断即丢数据
场景:对实时性要求高、允许轻微丢失的日志采集任务
1.4.4 Kafka Channel
引入版本:Flume 1.6
重新优化版本:Flume 1.7(修复了 topic-event 的 bug)
特性:
基于 Kafka 存储,可靠性高
速度快于 memory+sink 组合(减少 sink 阶段)
问题:
1.6 版本存在 topic-event 参数无效问题(true/false 都不起作用)
1.7 版本修复后性能显著提升
1.4.5 生产环境 Channel 选择建议
💡 类比:
“每天丢几百万条日志,就像亿万富翁掉 1 块钱,不值得去捡。”
1.5 Sink 模块 —— HDFS Sink
HDFS Sink 用于将数据写入 HDFS 文件系统。
数据的滚动方式由时间、文件大小或 event 数量控制。
关键参数:
hdfs.rollInterval=3600 # 每小时滚动一次
hdfs.rollSize=134217728 # 文件达到128MB滚动
hdfs.rollCount=0 # 不根据 event 数滚动
1.6 拦截器(Interceptor)
1.6.1 概述
拦截器用于在 Source → Channel 之间对数据进行 ETL(过滤、标注、格式化等)处理。
1.6.2 使用建议
可定义多个拦截器(模块化开发)
优点:灵活,可复用
缺点:性能下降,增加延迟
1.6.3 自定义拦截器开发步骤
实现
Interceptor接口重写以下方法:
initialize(); // 初始化 intercept(Event event); // 处理单个事件 intercept(List<Event> events); // 批量处理事件 close(); // 关闭资源编写静态内部类
Builder实现Interceptor.Builder
1.6.4 拦截器可不使用吗?
可以。
如果不使用拦截器,可在下游(Hive DWD、SparkStreaming)层进行清洗处理。
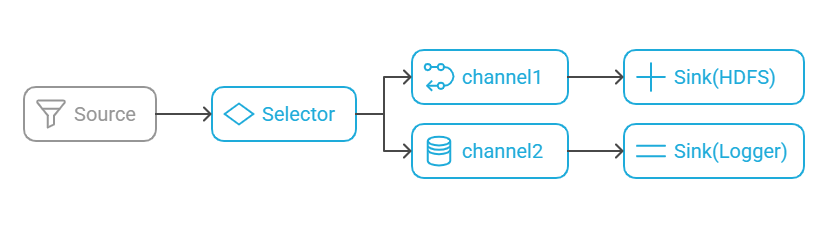
1.7 Channel Selector(通道选择器)
1.7.1 概述
Channel Selector 决定 event 进入哪个 Channel。
Replicating Selector(默认):复制 event 到所有 Channel
Multiplexing Selector:按条件将 event 发送到指定 Channel
📊 示意图:
1.8 Flume 监控与性能优化
1.8.1 监控工具
常用:Ganglia
观察指标:提交次数 vs 成功次数
若尝试次数远多于成功次数 → 性能瓶颈
1.8.2 优化手段
示例:
活动高峰(如 618)时可临时扩容日志采集节点。
1.9 Flume 防止数据丢失机制
✅ 推荐:
对关键日志(如订单、交易)必须使用 File Channel 或 Kafka Channel。
✅ 总结
💡 Flume 的精髓在于 事务机制 + 灵活组件组合,
在大数据采集体系中扮演“数据入口守门员”的角色。