🌀 Hadoop Shuffle 与优化
🧩 1️⃣ Shuffle 过程
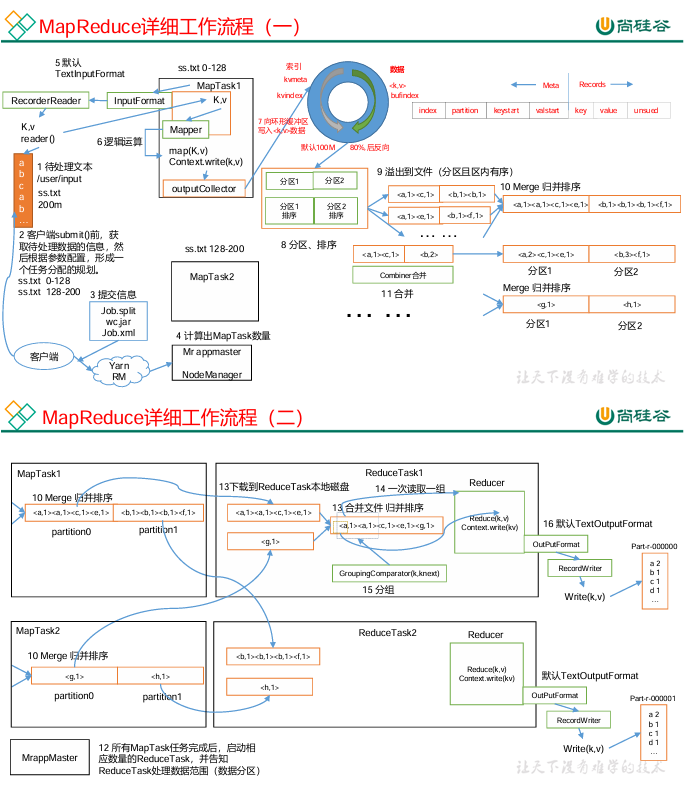
Shuffle 是 MapReduce 中 连接 Map 阶段与 Reduce 阶段 的核心过程,负责将 Map 端的输出结果分发到对应的 Reduce 节点。整个过程可分为以下几个阶段:
🔹 Map 端 Shuffle
Map 任务执行完成后输出数据到内存缓冲区(环形缓冲区);
当缓冲区使用率达到阈值(默认 80%)时,会触发溢写(Spill),将缓冲区数据写入本地磁盘;
在溢写过程中:
会对数据按 key 进行 排序(Sort);
若设置了 Combiner,则先局部聚合;
所有溢写文件在 Map 任务结束后,会进行 Merge(多路归并),生成最终输出文件;
最终 Map 输出的中间结果会通过 HTTP 传输给 Reduce 端。
🔹 Reduce 端 Shuffle
Reduce 任务启动后,首先从多个 Map 端 拉取(Copy) 属于自己的数据;
拉取完成后,进行 Merge + Sort;
进入 Reduce 函数 进行最终聚合计算;
输出结果写入 HDFS。
⚙️ 2️⃣ Shuffle 优化策略
🌱 (1)Map 阶段优化
优化项 | 说明 |
|---|
💾 增大环形缓冲区大小 | 默认 100MB,可调整为 200MB(mapreduce.task.io.sort.mb)。 |
📈 提高溢写比例阈值 | 从 0.8 调整到 0.9(mapreduce.map.sort.spill.percent)。 |
🔁 减少 merge 次数 | 控制溢写文件数,每次合并 20 个文件。 |
🔂 启用 Combiner | 在 Map 阶段提前聚合,减少 I/O 和网络传输。 |
🌾 (2)Reduce 阶段优化
优化项 | 说明 |
|---|
⚖️ 合理设置 Map/Reduce 数量 | 数量太少会等待、太多会竞争资源。 |
⏱ Map 与 Reduce 共存 | 调整参数 mapreduce.job.reduce.slowstart.completedmaps,让 Reduce 在 Map 完成部分后启动。 |
🚫 避免不必要的 Reduce 操作 | 对于简单处理任务,可跳过 Reduce,节省网络传输。 |
🚀 增加并行拉取数 | 提高 Reduce 拉取 Map 数据的线程数。 |
💡 增大 Reduce 缓冲区 | 调整 mapreduce.reduce.shuffle.input.buffer.percent。 |
📡 (3)I/O 与压缩优化
优化点 | 说明 |
|---|
🧱 压缩传输数据 | 减少网络 I/O 时间,推荐安装 Snappy、LZO。 |
🗜 Map 输入端压缩 | 支持切片的格式:Bzip2、LZO(需建索引)。 |
⚡ Map 输出端压缩 | 注重速度:Snappy、LZO。 |
📦 Reduce 输出端压缩 | 长期保存用 Gzip,下一任务输入需支持切片格式。 |
🧮 (4)整体资源与参数优化
优化方向 | 参数 | 建议 |
|---|
🧠 NodeManager 内存 | yarn.nodemanager.resource.memory-mb
| 例如 128G 机器配置为 100G。 |
💾 单任务内存 | yarn.scheduler.maximum-allocation-mb
| 控制任务最大可分配内存。 |
🧰 Map 内存上限 | mapreduce.map.memory.mb
| 默认 1G,可增至 4–5G。 |
🧰 Reduce 内存上限 | mapreduce.reduce.memory.mb
| 默认 1G,可增至 4–5G。 |
☕ Map 堆内存 | mapreduce.map.java.opts
| 防止 OutOfMemoryError。 |
☕ Reduce 堆内存 | mapreduce.reduce.java.opts
| 同上。 |
⚙️ CPU 并行度 | 调整容器核数 | 增加 Map/Reduce 并行能力。 |
💽 多目录配置 | dfs.datanode.data.dir
| 分散 I/O 压力。 |
🧵 NameNode 线程池 | dfs.namenode.handler.count
| 推荐:20 * log2(Cluster Size)。 |
🧠 Yarn 工作机制
YARN(Yet Another Resource Negotiator)是 Hadoop 的 资源管理与调度框架,负责任务的资源分配与监控。
📋 主要组件:
组件 | 功能 |
|---|
🧩 ResourceManager(RM) | 集群全局资源管理与任务调度中心。 |
🔄 NodeManager(NM) | 每个节点的资源与任务监控执行器。 |
📦 ApplicationMaster(AM) | 每个应用的任务协调者,负责 Map/Reduce 任务生命周期管理。 |
🧠 Container | 承载任务运行的资源单位(CPU + 内存)。 |
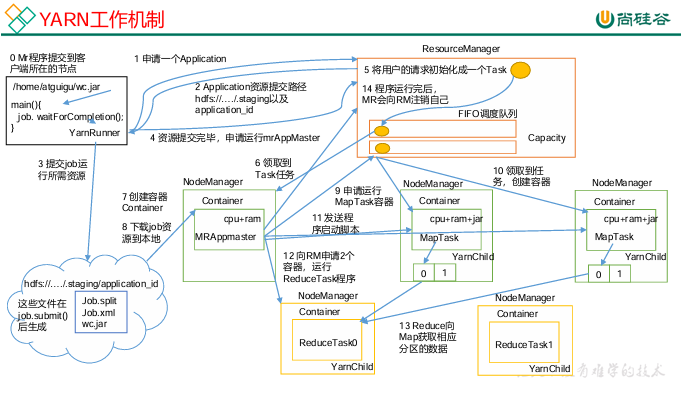
🚀 执行流程:
Client 提交任务到 ResourceManager;
RM 分配 ApplicationMaster;
AM 向 RM 申请资源(Container);
NodeManager 启动任务;
任务完成后汇报状态给 RM;
RM 释放资源。
🧭 Yarn 调度器
🎛️ 1️⃣ 三种调度器类型
调度器类型 | 特点 | 是否多队列 | 生产环境 |
|---|
🕐 FIFO | 单队列、先进先出 | ❌ | ❌ 不推荐 |
🧮 Capacity Scheduler | 多队列、按容量分配 | ✅ | ✅ 常用 |
⚖️ Fair Scheduler | 多队列、公平共享 | ✅ | ✅ 大厂常用 |
👉 Apache 默认:Capacity Scheduler
👉 CDH 默认:Fair Scheduler
🗂️ 2️⃣ 多队列配置与优势
多队列配置方式:
按框架划分(Hive、Spark、Flink)
按业务模块划分(注册、下单、推荐等)
优势:
防止单个任务占满全部资源;
保障核心业务优先级;
支持资源降级调度;
任务隔离性更好。
⚡ Hadoop 性能测试(Benchmark)
搭建 Hadoop 集群后应执行基准测试,验证:
HDFS 的读写性能;
MapReduce 的计算性能。
测试 JAR 文件在 Hadoop 的 share 目录下,例如:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO
💥 Hadoop 宕机与优化
场景 | 原因 | 解决方案 |
|---|
🧨 MR 任务导致系统宕机 | Yarn 并发任务过多,内存耗尽 | 调整 yarn.scheduler.maximum-allocation-mb 限制单任务最大内存 |
💾 写入过快导致 NameNode 宕机 | Kafka→HDFS 写入压力过大 | 限制 Flume 批次大小(batchsize)或 Kafka 缓冲区大小 |
⚖️ Hadoop 数据倾斜问题与解决方案
数据倾斜 是指部分 key 的数据量过大,导致个别 Reducer 处理时间过长。
🎯 原因
某些 key 数据分布极不均衡;
Map 输出 key 数量分布不均;
自定义分区函数不合理。
💡 解决方案
方法 | 原理 | 场景 |
|---|
🧮 Combiner | 在 Map 阶段局部聚合,减少 Shuffle 传输数据量 | 适用于聚合类操作(sum/count) |
🔀 随机前缀法 | 在 key 前加随机前缀,使其分散到不同 Reducer;再进行二次聚合 | 大量集中 key |
⚙️ 增加 Reducer 数量 | 提高并行度,减少单节点压力 | 数据量大时 |
🧩 自定义分区器 | 根据 key 的特征设计分区函数 | key 分布不均时 |
🔁 两阶段 MR 聚合 | 第一次局部随机散列,第二次全局聚合 | 超大规模倾斜数据 |
🧮 集群资源分配问题
现象:
集群 30 台机器,但所有 Map 任务集中在同一台机器上。
原因:
YARN 默认允许单节点运行多个任务副本,未做资源均衡分配。
解决方案:
yarn.scheduler.fair.assignmultiple = false
关闭该参数可让任务在节点间更均匀分配。

