

1. 常用资源调度器类型(Scheduler)
大数据集群中,多用户、多任务并发运行时,调度器负责决定任务如何排队、如何分资源。
YARN 支持三大调度器:
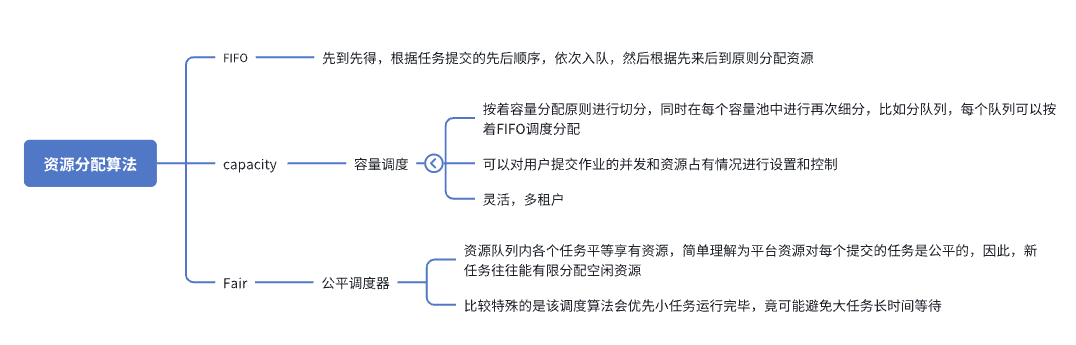
🔹 1.1 FIFO(先进先出调度)
核心思想:先来先服务
提交早的任务优先执行
按顺序排队处理
实现简单、不支持多租户资源隔离
缺点:
大任务会阻塞后续所有任务
小任务延迟大
适用场景:
测试环境、小规模集群
🔹 1.2 Capacity Scheduler(容量调度器)
核心思想:为每个队列分配固定 / 最小资源容量(多租户最常用)
特点:
队列有容量配额,可限制用户并发数量
支持队列之间“资源借用”
队列内部可继续按 FIFO/Fair 等策略调度
实现真正的多租户资源隔离
适用场景:
企业集群、多部门共享资源平台(最常用)
🔹 1.3 Fair Scheduler(公平调度器)
核心思想:所有任务平均获得资源,公平共享
特点:
不因先后顺序影响任务资源获取
新任务也能立即获得资源
小任务优先运行,加速交互式任务
队列之间仍可设置“最小资源保障”
适用场景:
交互式分析(Hive/Spark)、大量短任务并发环境
🔸 1.4 调度器小结
关键点:
Capacity 与 Fair 都是 “以队列 Queue 为一级资源管理单元”。
2. YARN 整体架构(Master / Slave)
YARN 采用主从架构,类似 HDFS(NameNode / DataNode)。
核心目标:
统一资源管理,让 MR / Spark / Flink 等多种计算引擎共享资源。
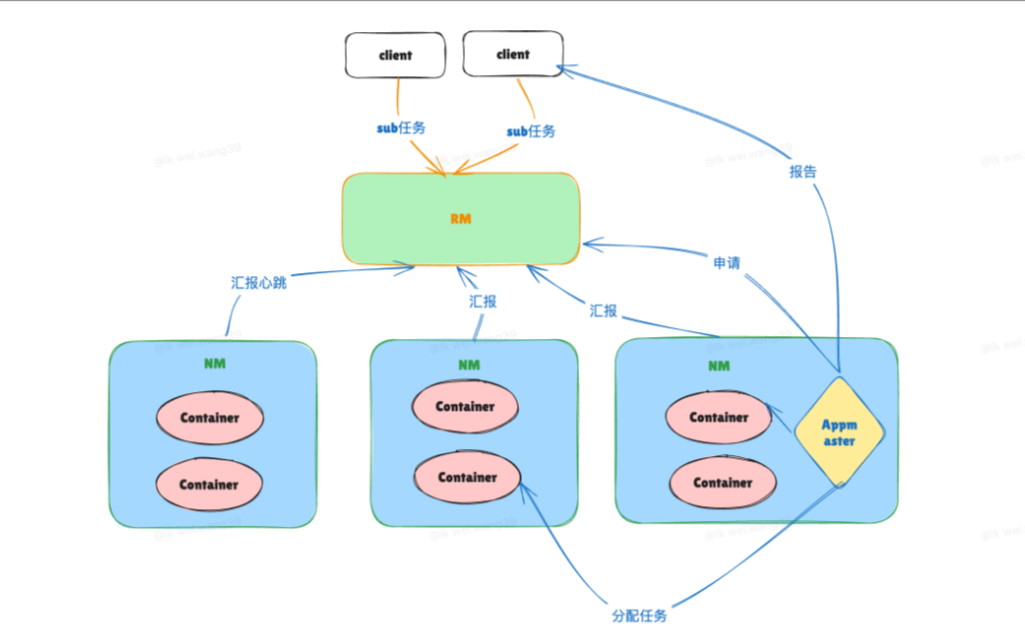
🔵 2.1 ResourceManager(RM)—— 集群大脑
职责:
管理全局资源
接收作业提交
调用调度器进行资源分配
与 NodeManager 交互(心跳机制)
为 AM 分配 container
类似 HDFS 中的 NameNode。
🟢 2.2 NodeManager(NM)—— 节点资源管理者
职责:
本机资源汇报给 RM
启动 / 停止 container
监控任务运行状态
负责 CPU / 内存等资源的执行层实现
类似 DataNode,但管理的是资源而不是数据。
🟣 2.3 ApplicationMaster(AM)—— 作业协调者
每个应用启动一个 AM,负责:
向 RM 申请资源
与 NM 通信启动 Task
执行失败重试、监控任务状态
维护整个作业生命周期
不同计算框架有不同 AM:
MR 的 AM
Spark 的 AM
Flink 的 AM
🟠 2.4 Container(资源容器)
YARN 最小资源单位,包含:
CPU
内存
环境变量
执行命令
container 是动态创建的,任务按 container 启动。
3. YARN 工作机制总结
YARN 只负责 资源调度
计算由不同引擎执行,如:
MapReduce
Spark
Flink
存储也独立(HDFS / 对象存储 / HBase),实现三者完全解耦:
存储 ↔ 计算 ↔ 资源管理
4. YARN 作业提交与执行流程(重点)
YARN 作业执行流程核心如下:
客户端 → RM → AM → RM → NM → Container → 执行任务
下面是详细流程:
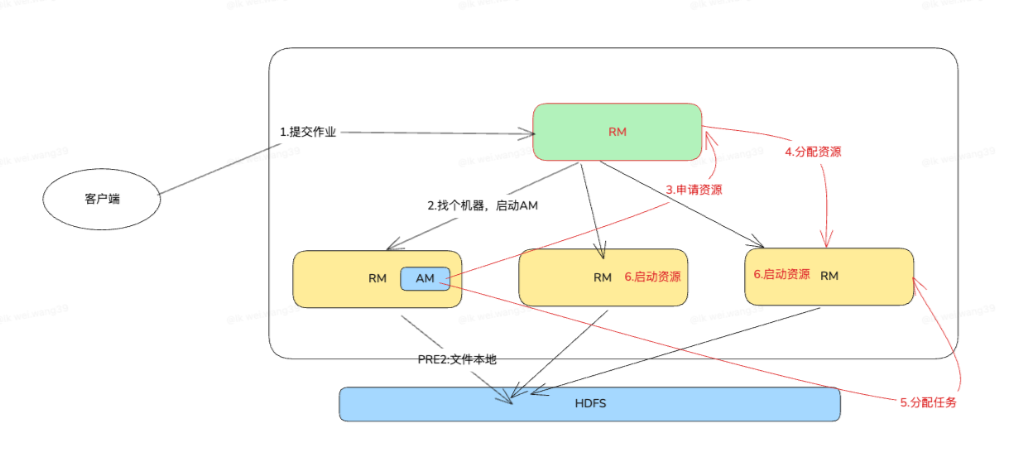
🔄 4.1 提交流程详解
1)Client 提交作业
将作业信息(JAR、配置、队列、资源需求)提交给 RM
2)RM 接收请求并分配 AM
选择一个 NM
创建 container
启动 AM
3)AM 启动并注册
向 RM 注册并声明:可以开始调度任务了
4)AM 向 RM 请求资源
如 MR:
请求 Map 所需 N 个 container
再请求 Reduce 所需 M 个 container
如 Spark:
请求 Executor container
5)RM 分配资源并返回 AM
调度器(Capacity/Fair)根据规则选择节点
分配 container 给 AM
6)AM 与对应的 NM 通信
让 NM 启动对应的 task/Executor
7)任务在 Container 中运行
实际执行 MR task / Spark executor / Flink taskmanager
状态由 NM 心跳反馈给 RM 和 AM
⭐ 4.2 关键机制说明(面试常问)
✔(1)数据本地化(Data Locality)
优先在“数据所在节点”运行任务,减少网络流量。
本地性等级:
Node Local(最佳)
Rack Local(可接受)
Off-rack(最差)
✔(2)RM 依赖 NM 汇报资源信息
RM 不会主动探测资源,全靠心跳回传。
✔(3)container 状态由 NM 负责
RM 不直接监控任务进程。
5. MapReduce 作业在 YARN 中的完整执行过程
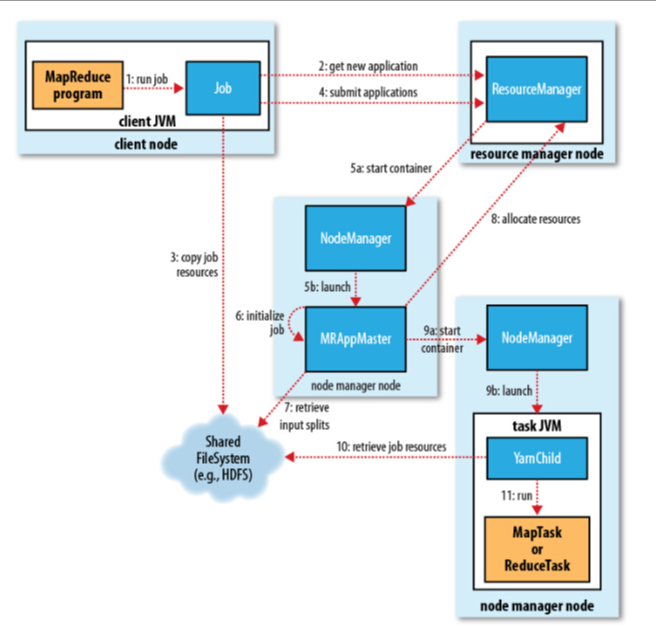
Client 提交 MR 作业
RM 启动 MapReduceAppMaster
AM 向 RM 申请 MapTask container
NM 启动 MapTask
Map 结束 → Shuffle → Reduce
AM 汇报任务完成
RM 清理资源,作业结束
整个过程完全运行在 YARN 资源调度体系内。
🎯 最终总结
本笔记完整覆盖:
YARN 三大调度器(FIFO / Capacity / Fair)
使用场景与核心差异
YARN 主从架构与组件职责
RM / NM / AM / Container 全面解析
作业提交、调度、执行全流程
数据本地化原则
MR 在 YARN 上的运行机制