

本笔记详细介绍 Doris 底层存储结构 Segment V2、文件格式组成、索引区域设计、Bitmap 正交去重原理、主键模型并发控制机制 等知识点。
🧱 1. Doris 的底层文件存储结构(Segment V2)
Doris 底层文件存储设计大量参考 ORC File,使用 Segment V2 文件格式 作为最小的数据存储与索引组织单元。
📁 1.1 Doris 数据存储分层结构
Doris 表数据的落盘结构大体如下:

其中:
Partition 解决大数据集管理、冷热分层等问题
Bucket(Tablet) 是分布式存储的基本分散单元
Rowset 表示一个数据写入批次或版本
Segment 是 最小的存储文件单元,包含数据与索引
📦 2. Segment 文件格式详解
Segment 文件内容结构如下:
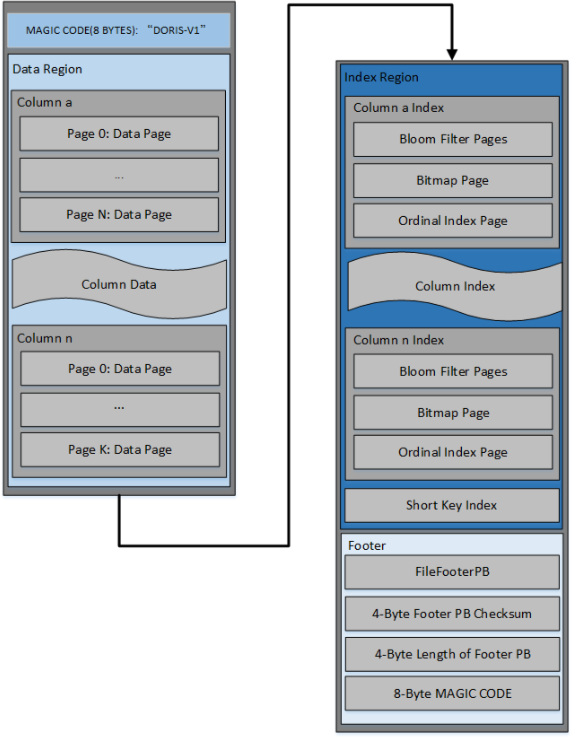
🔍 2.1 Data Region(数据区)
按 列式存储
每列按多个 Page(64KB) 切分
Page 是最小的读取单元
Data Page 内包含:
压缩数据
字段编码信息
Null Bitmap 等
📑 2.2 Index Region(索引区)
Doris 索引非常丰富,用于加速过滤 & 快速定位数据:
在查询时,Doris 会根据过滤条件动态加载对应索引,从而降低 IO。
🦶 2.3 Footer(文件尾部)
Footer 主要包含:
SegmentFooterPB:记录整体结构信息
Checksum:校验完整性
PB Length:Footer 结构大小
MAGIC CODE:文件尾标识
Footer 是整个文件的“说明书”,Doris 启动查询时优先读取这里的内容。
🧮 3. Doris 正交 Bitmap(Orthogonal Bitmap)原理与使用
正交 Bitmap 是 Doris 提供的一种 高效去重计算优化 技术,用于提升 UV / 去重计数场景的性能。
🎯 3.1 背景:为什么需要正交 Bitmap?
传统方案(Doris / Spark 都一样):
全量用户 id bitmap 放在同一 FE 或同一任务中
Bitmap 可能超过 500MB–1GB
计算速度明显下降,引发性能瓶颈
尤其在:
UV 计算
用户数去重
高频维度统计
都会出现瓶颈。
🔧 3.2 解决思路:分桶 + 分而治之
核心思路:
将用户 ID 通过 Hash 分桶
每个桶单独生成 bitmap
最终只需要对各桶 bitmap 的 “cardinality” 求和即可
这是一种 正交(Orthogonal)拆分,不同桶之间互不影响。
⭐ 优点:
不同桶之间互斥 → 不会重复计数
Bitmap 尺寸大幅下降
查询速度显著提升
支持高度并行化
🚀 3.3 Spark 离线处理示例(原理介绍)
假设表结构如下:
user_id BIGINT COMMENT '用户id'
bucket_no INT COMMENT '分桶号'
分桶方式:
bucket_no = hash(user_id) % N
之后聚合:
SELECT dim1, dim2, bucket_no,
bitmap_union(user_id) AS bucket_uv
FROM test.table
GROUP BY dim1, dim2, bucket_no;
最终:
SUM(bucket_uv) = 全局 UV
🔥 3.4 Doris 内置正交 Bitmap
Doris 2.0 已提供内置支持:
官方文档(说明用,无需访问)orthogonal-bitmap-manual
应用场景包括:
大规模 UV 统计
复杂多维去重
高并发查询场景
🔐 4. Doris 主键模型的并发控制(Unique Key + Sequence Column)
在实时与离线写入场景中,并发更新主键 会出现覆盖冲突问题。
Doris 引入类似 HBase 的 版本号控制机制(Sequence Column) 来保证最终一致性。
🎯 4.1 背景问题
多写入源同时更新同一个主键:
写入顺序非严格有序
不同批次会互相覆盖
数据可能回退
最终结果不正确(如首单、最早时间等)
🔧 4.2 Doris 的解决方案:Sequence Column
Doris 提供:
Sequence Column(版本列)
高版本覆盖低版本(与 HBase 类似)
结合 Unique Key,可保证数据最新性
写入时一般:
sequence_col = event_time 或 batch_time
越大代表越新。
🧰 4.3 应用场景
⭐ 场景1:极值获取(首单、最早时间)
例如:
order_time 最小 → 首单时间
将 order_time 作为 sequence column,Doris 会自动取:
最早 order_time 的记录
⭐ 场景2:防回退 + 并发更新控制
在多源写入用户表、资产表、订单表时,可以防止:
旧数据覆盖新数据
程序异常导致回滚写入
📝 5. Example:典型首单查询逻辑
首单场景典型数据写入方式:
sequence column =
order_time较小值优先(因为表示更早)
例如占位时间设定为:
9999-12-31 00:00:00
写入后 Doris 根据 sequence column 自动保持:
主键唯一
时间最早的记录
🎉 结语
通过以上内容,我们全面整理了 Doris 的核心底层机制:
Segment V2 存储结构
数据与索引区域细节
正交 Bitmap 的性能优化原理
主键模型并发控制的序列号机制