

🟦 1. Doris 系统整体架构概览
Doris(Apache Doris)是一个高性能、实时、统一的 MPP(Massively Parallel Processing)分析型数据库,专注于:
高并发低延迟查询(秒级甚至毫秒级)
存储与计算层面高压缩 + 快速向量化处理
处理实时 + 离线数仓数据场景
统一数仓架构(支持明细存储、聚合存储、主键更新、物化视图)
海量数据下的高速多维分析
Doris 采用了分布式架构,并融合了多个优秀系统的理念:
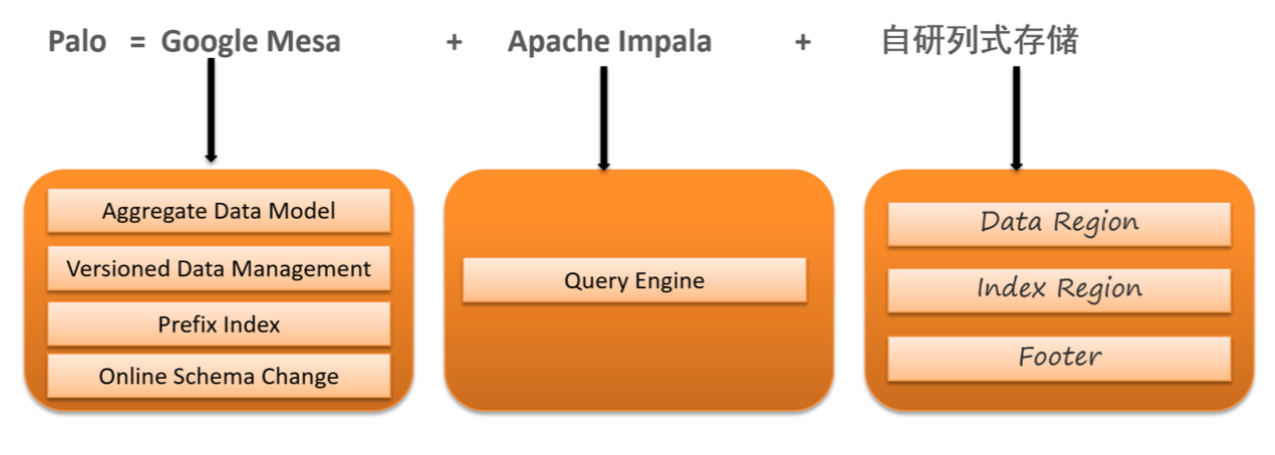
📌 Doris 并非某个系统的简单优化版,而是融合创新后的完整 OLAP 数据库。
🟦 2. Doris 架构演进:从简单到云原生
Doris 的架构发展经历了两个阶段:
⭐ 2.1 Doris 3.0 之前:存算一体架构(经典、稳定、简单)
在 3.0 以前,Doris 整体架构十分简洁,只有 FE 和 BE 两类核心角色。
🖇 整体结构如下:
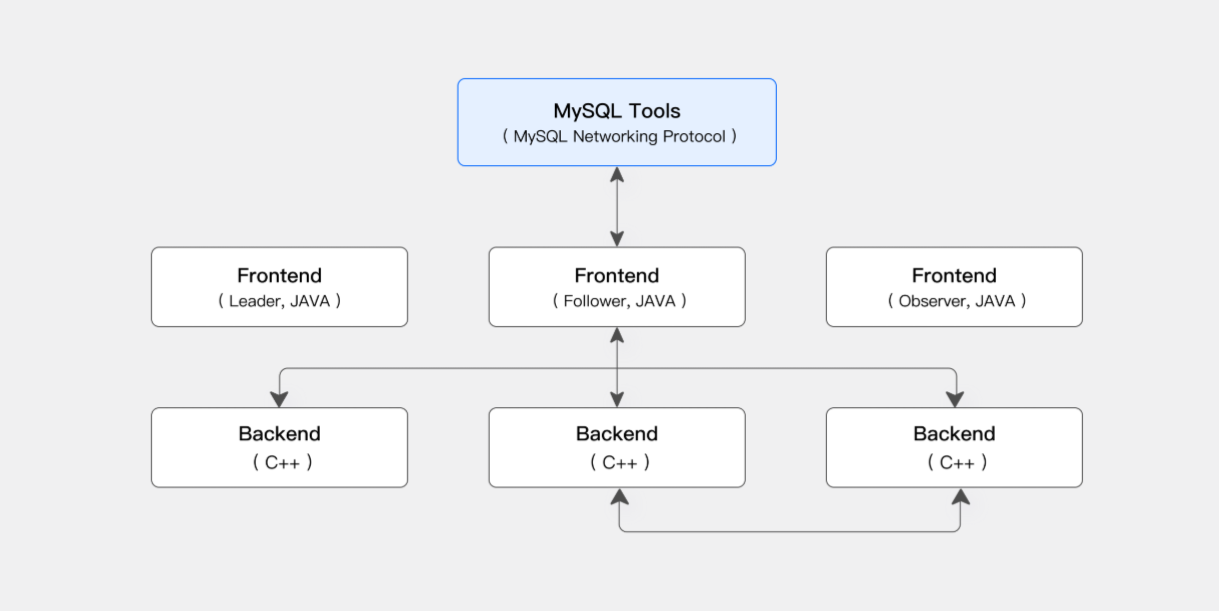
🧩 2.1.1 FE(Frontend)角色的详细说明
FE 是 Doris 的“大脑”,负责:
🧠 A. 请求管理
接受 MySQL 协议请求(兼容 MySQL 客户端)
执行 SQL 语法解析(Parser)
执行语义分析(Analyzer)
生成查询计划(Planner)
🗂 B. 元数据管理(核心职责)
掌管全库“结构层”信息,包括:
表结构、分区结构、索引信息
Tablet 路由信息(BE 链接路线)
数据版本信息(rowset 元信息)
事务信息(导入事务、版本提交等)
🔄 C. 节点管理
负责 BE 节点加入 / 退出管理
健康检查
元数据复制与一致性维护
🧩 2.1.2 FE 的 Master / Follower / Observer 区别详解
📌 企业常见部署方式
1 Master + 2 Follower(保证高可用)
可按需增加若干 Observer 用于提升查询吞吐
🔐 2.1.3 FE 元数据一致性机制(非常重要)
Doris 使用 Paxos 协议 来保证 FE 多节点之间的数据一致性。
元数据持久化采取“三套机制联合”:
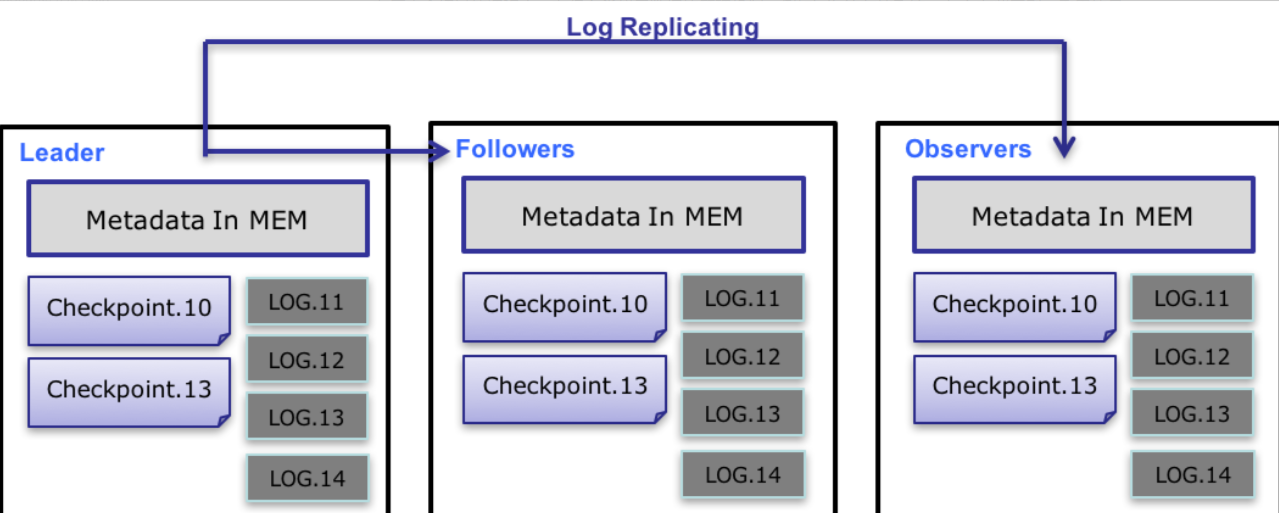
Memory
元数据常驻内存,用于高速访问
Journal(WAL,预写日志)
每次元数据变更先写日志再写内存
通过日志同步到其他 FE 节点
Checkpoint
定期将内存数据快照化写入磁盘
避免日志无限体积增长
📌 执行顺序如下:
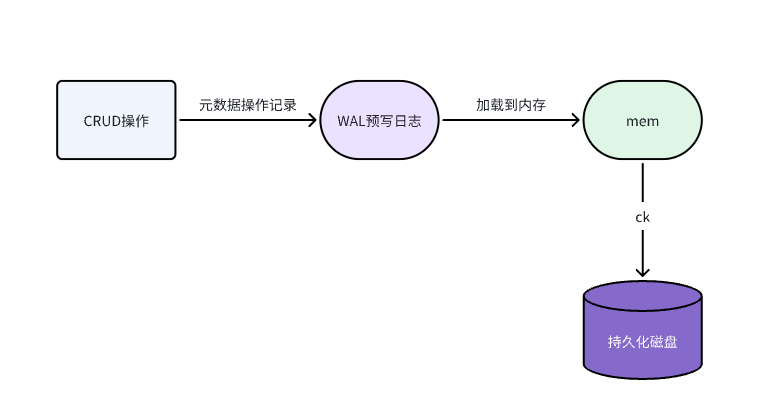
元操作产生(DDL/ 事务提交)
写入 Journal(WAL 预写日志)
更新内存元数据
Journal 同步到其他 FE
周期性 Checkpoint 保存内存快照
⭐ 2.2 BE(Backend)详细说明
BE 是 Doris 的“心脏”,负责:
🔢 数据存储(列式)
Segment 文件(自研列式格式)
多副本存储机制(默认 3 副本)
高效索引(前缀索引、BloomFilter)
⚡ 查询执行(向量化执行框架)
主流程:Scan → Filter → Hash → Join → Aggregate
向量化执行避免逐行处理,大幅提升性能
支持编译执行 Pipeline
🔁 数据管理
Compaction(合并小文件、清理版本)
Tablet 负载均衡
删除标记处理(害怕数据膨胀)
🟦 3. 存算分离架构(Doris 3.0+)
🎯 存算分离的目标
更灵活的资源扩缩容
更低的存储成本(S3 / OSS 等)
更强的多租户隔离
更符合云原生部署趋势
Doris 3.0 将原先的 FE 与 BE 职责进一步细分,使架构成为工业级标准:
⭐ 3.1 三层架构分层说明
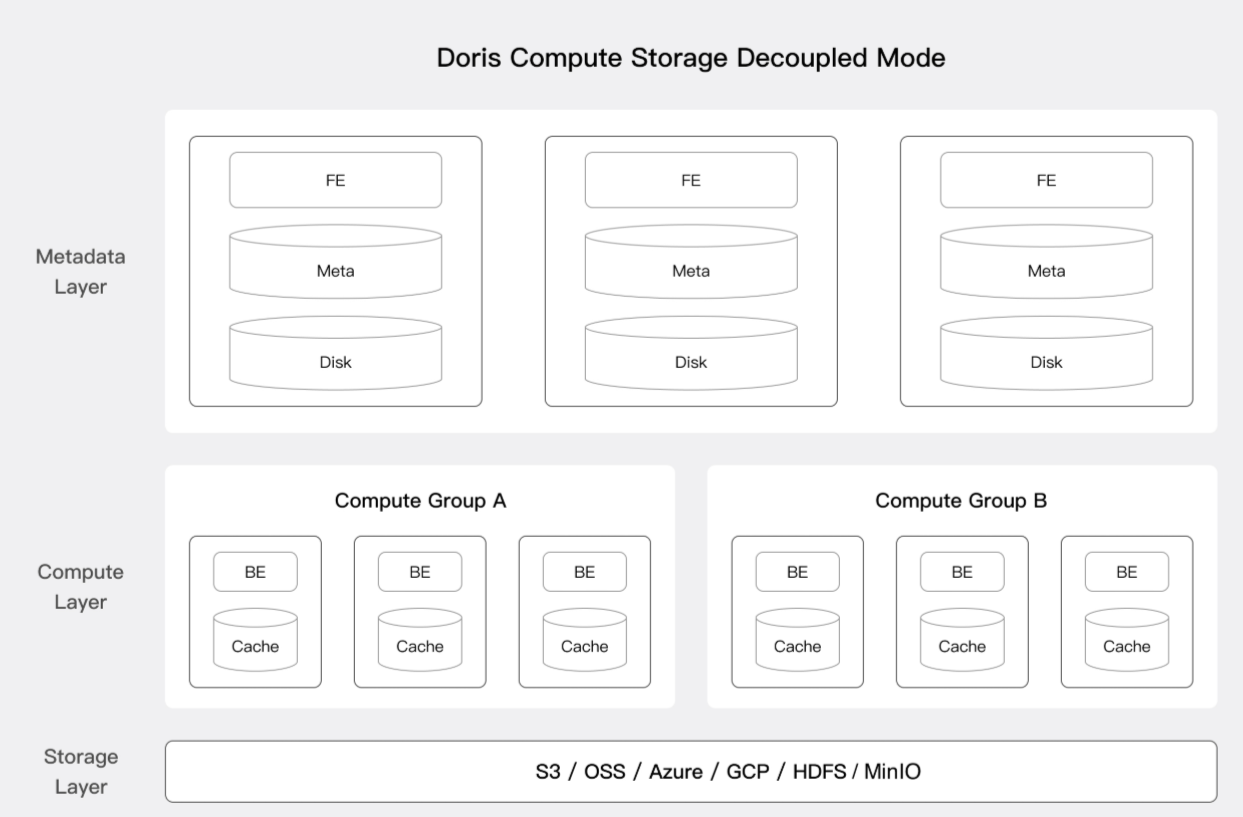
⭐ 3.2 元数据层(Meta Layer)
承担 FE 的元数据管理职责
维护查询计划、租户配置、表元信息
高可用保证数据一致性
➕ 元数据操作从 BE 中剥离,提高集群稳定性。
⭐ 3.3 计算层(Compute Layer)
由多个 Compute Group 组成,每组可视为一个租户
每组可以独立:
资源管理
任务调度
并发控制
集群扩缩容
BE 在这一层变成 无状态执行节点,可以轻松:
扩容
缩容
失效节点自动替代
⭐ 3.4 存储层(Storage Layer)
存储层支持多种对象存储:
S3
OSS / COS / OBS
MinIO
Ceph
HDFS
使用对象存储的好处:
低成本(比自建服务器硬盘便宜)
无限扩容
数据天然高可用
多地多活
🟦 4. Doris 自研列式存储架构(核心能力)
Doris 的存储引擎经过高度定制,服务于高性能分析。
⭐ 4.1 Segment 文件(核心)
Segment 是 Doris 的物理存储单位,包含:
数据页(Data Pages)
列数据编码(Dictionary、RLE、Bitmap…)
索引数据(Prefix Index)
Footer(元信息)
特点:
按列存储(Column-oriented)
高压缩
按需读取
高效并行扫描
⭐ 4.2 Prefix Index(前缀索引)
对排序键列生成前缀索引,可快速定位:
范围查询
点查
Join Probe 时加速 Key 查找
⭐ 4.3 Data Region & Index Region
Data Region:列数据 + 编码
Index Region:前缀索引、BloomFilter、ZoneMap
配合向量化执行实现极快查询
🟦 5. Doris 数据模型(极其关键)
Doris 的三大模型面向不同业务场景:
⭐ 5.1 Aggregate 模型(聚合模型)
有聚合键(Key Columns)
Value 列自动做聚合
类似物化视图聚合
✔ 适合报表、指标类数据
⭐ 5.2 Unique 模型(主键模型)
支持主键唯一性
支持更新(Merge-on-Write)
✔ 适合 CDC 数据、业务明细表
⭐ 5.3 Duplicate 模型(重复模型)
不做聚合,也不做唯一性控制
✔ 适合日志、宽表数据
🟦 6. 存算一体 vs 存算分离(总结)
📌 结论:存算分离是未来趋势,适用于大规模企业级场景。
🟦 7. 总结(Rich Version)
Doris 结合多种系统优势,真正实现了高性能 + 实时 + 统一的数据平台能力
从 3.0 起支持云原生的存算分离架构,是 OLAP 方向最具潜力的系统之一
其自研存储格式、向量化执行引擎、Paxos 元数据一致性等技术共同构建了 Doris 的高性能基础
适用于中小企业到大型集团的多种数仓与分析场景
在湖仓一体、实时数仓、多租户资源池、企业分析体系中表现出色