

1. Spark 的部署方式 🚀
Spark 支持多种部署方式,以满足不同的开发、测试和生产环境需求。
2. Spark 作业提交方式
在生产环境中,Spark 作业主要通过 Shell 脚本命令行 提交,而不是 JavaEE 界面。
✅ 常用提交脚本样式:
spark-submit \
--master yarn \
--deploy-mode cluster \
--class com.company.app.MainClass \
--driver-memory 8g \
--executor-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--name "UserLogETLJob" \
app.jar input_path output_path
常见参数说明:
3. Spark 架构与作业提交流程(重点)
Spark 运行时由以下组件组成:
Driver:运行用户的
main()方法,负责任务划分和调度。Executor:执行具体任务并将结果返回给 Driver。
Cluster Manager:资源调度器,如 YARN 或 Standalone。
Worker Node:实际运行 Executor 的节点。
🌐 Yarn-Client 模式流程(Driver 在客户端)
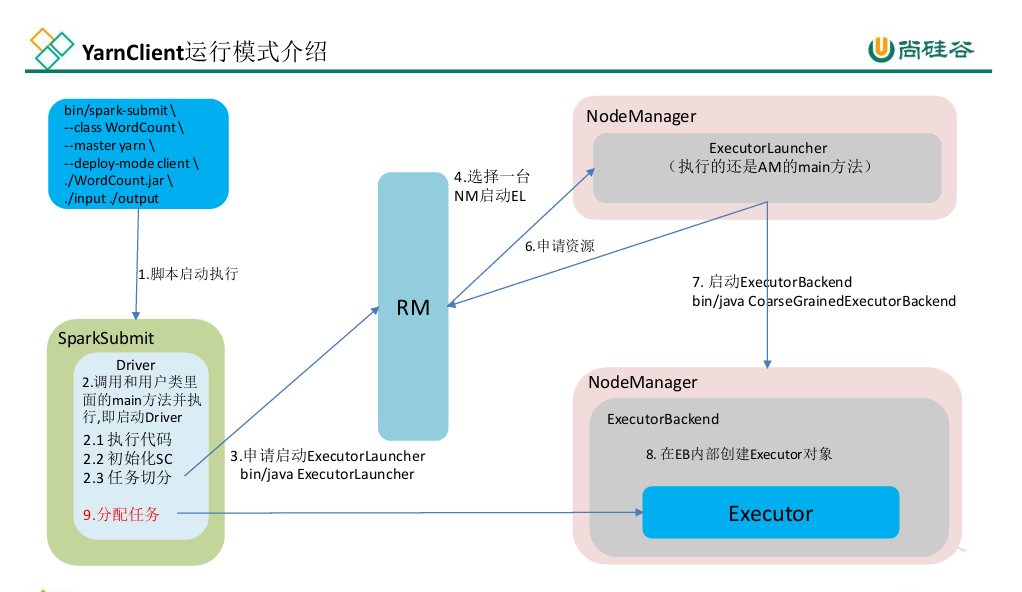
启动脚本 → 执行
SparkSubmit。初始化 Driver 并创建 SparkContext。
Driver 划分 Job → Stage → Task。
向 YARN ResourceManager 申请资源。
ResourceManager 分配 NodeManager。
NodeManager 启动 ExecutorBackend。
Executor 注册到 Driver 并执行任务。
⚙️ Yarn-Cluster 模式流程(Driver 在集群)
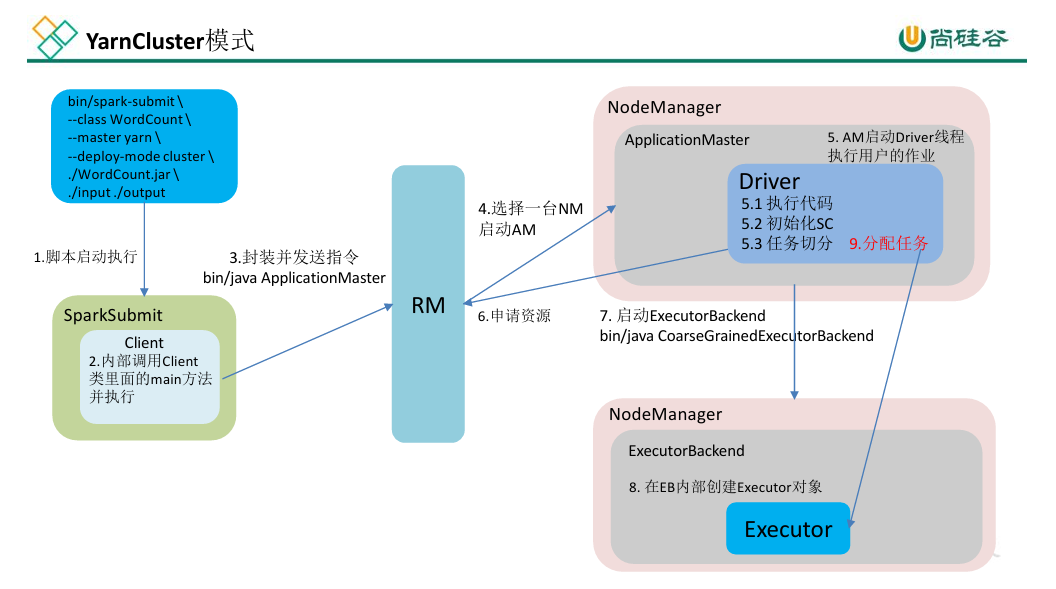
客户端提交任务给 YARN。
YARN 启动 ApplicationMaster。
AM 内启动 Driver 线程执行用户逻辑。
Driver 申请 Executor 资源。
NodeManager 启动 ExecutorBackend。
Executor 执行任务并返回结果。
4. Spark 的 RDD 血统(Lineage)机制
RDD(Resilient Distributed Dataset) 是 Spark 的核心抽象。
RDD 具有 血统(Lineage),即记录了其由哪些 RDD 经过哪些转换(transformation)得到。
✳️ 优势:
无需数据副本即可实现容错:当部分数据丢失时,可根据 lineage 重新计算。
可用于任务调度优化和失败恢复。
🔗 依赖类型:
5. Stage 与 Task 划分规则
Stage 划分:遇到一个 宽依赖 就会产生新的 Stage。
Task 划分:一个 Stage 内部根据 分区数(Partition 数) 生成对应数量的 Task。
示例:
map → reduceByKey
map 是窄依赖(同 Stage)
reduceByKey 是宽依赖(需 Shuffle,触发新 Stage)
6. 常见 Transformation 算子汇总 💡
7. Spark 性能调优思路总结 🧩
✅ 使用合适的算子:
reduceByKey替代groupByKey。✅ 尽量使用广播变量(Broadcast) 减少数据传输。
✅ 使用缓存与持久化(cache/persist) 提高重复计算性能。
✅ 合理设置并行度:
spark.default.parallelism一般为集群核数的 2–3 倍。✅ 避免数据倾斜:通过随机前缀或 map-side combine。
✅ 压缩与序列化优化:采用 Kryo 序列化、Snappy 压缩。
✅ 资源参数调优:合理设置 executor 核数与内存,避免 OOM。